
Articut
Articut 服務介紹
基於人類習得語言的機制,透過「語法規則」建立中文語言處理的斷詞系統。
只用結構就能解決中文斷詞問題,不需要大數據,修改快且離線就能跑。
沒有內建字典,不認識的詞彙都是 OOV,不需要擔心新詞彙出現,無法處理。
不只有斷詞,它還能推理詞性標記 (POS) 與命名實體 (NER)。
同時計算 中文斷詞 + 詞性標記 + 命名實體
讓電腦把詞彙以「在該句子內的意義」為單位切割出來。
使用 Articut API
詳細的使用範例可參考 Github 上 ArticutAPI。
HTTP Request
POST https://api.droidtown.co/Articut/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Articut Docker 版本無需設定此參數。 |
| api_key | str | "" | 在本站購買斷詞服務額度,完成付費後取得的一個具有 31 字符長度的字串。Articut Docker 版本無需設定此參數。 |
| input_str | str | "" | 將要送上 Articut 進行斷詞暨詞性標記處理的文字。注意!每次最大長度不得超過 2000 個字符。 |
| version | str | "latest" | 指定版本是選用的。如果此項留白,或指定 "latest",則 Articut 將使用最新版本的演算法對您上傳的文字進行斷詞。此外,您也能指定 Articut 的演算法版本。例如,若在此項輸入字串 "v001",則將會使用 v001 版本的斷詞演算法對您上傳的文字進行斷詞。 |
| level | str | "lv2" | 可為 "lv1"、"lv2" 或 "lv3"。指定為 lv1 時,將直接透過句子本身的語法結構進行推算,可視為「沒有百科知識」,只有語法能力的斷詞結果。若指定為 lv2 時,則會額外引入卓騰的百科知識庫輔助運算。若指定為 lv3 時,能夠計算出人、事、時、地、物、數字及拼音。 |
| user_defined_dict_file | dict | {} | 使用者自定詞典,必須是 dictionary 格式。 (e.g. UserDefinedDICT = {"key": ["value1", "value2",...],...})。 |
| opendata_place | bool | False | 政府開放平台 OpenData 中存有「交通部觀光局蒐集各政府機關所發佈空間化觀光資訊」。Articut 可取用其中的資訊,並標記為 <KNOWLEGED_place>。 |
| wikidata | bool | False | 取自 Wikidata 資料的中文名稱 (Label),並標記為<KNOWLEGED_wikiData>。Wikidata 不包含以下類型: |
| - 單一文字 (不含週期表元素) | |||
| - 電影、戲劇、節目名稱 (含系列) | |||
| - 電玩遊戲名稱 (含系列) | |||
| - 漫畫、動畫名稱 | |||
| - 小說、書本名稱 | |||
| - 專輯、歌曲名稱 | |||
| - 藝術作品名稱 | |||
| - 提名或入圍獎項 | |||
| - 動詞、時間 | |||
| - Wikimedia、Wikidata 列表 | |||
| chemical | bool | True | Articut 能夠辨識出化學成分,並標記爲<KNOWLEDGE_chemical>。如果文本中沒有化學物質,可關閉功能加快執行速度。 |
| emoji | bool | True | Articut 能夠偵測出 Emoji 符號,並標記爲<ENTITY_oov>。如果文本中沒有 Emoji 符號,可關閉功能加快執行速度。 |
| time_ref | str | "" | "lv3" 功能,時間格式:"yyyy-mm-dd HH:MM:SS",將 input_str 的句子內的時間依據此參數時間為基準,計算句子裡的相對時間或絕對時間並回傳 datetime 格式。例如: input_str = "蔡英文總統在今年五月二十日就職",time_ref = "2016-01-01 00:00:00",結果為 datetime = "2016-05-20 00:00:00";若無,則會依據系統時間為基準計算最接近的時間, 假設目前 系統時間 = 2020-10-01,結果為 datetime = "2020-05-20 00:00:00"。 |
| pinyin | str | "BOPOMOFO" | "lv3" 提供 "BOPOMOFO" 與 "HANYU" 兩種,文字轉聲音的標記 (包含破音字)。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到斷詞結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成斷詞作業。 | ||
| - Specified version does not exist.: 無法找到您指定的演算法版本。請再檢查一次您指定的演算法版本值。 | ||
| - Specified level does not exist.: 無法找到您指定的知識程度。知識程度只能為 "lv1"、"lv2" 或 "lv3"。 | ||
| - Authtication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid Articut key.: 無效的 api_key。請再檢查一次您的 api_key 是否正確。 | ||
| - Your input_str is too long. (over 2000 characters.): input_str 超過 2000 字符。 | ||
| - Insufficient word count balance.: 您帳號下的字數餘額不足以處理本次斷詞需求。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳斷詞結果的情況下,您帳號的餘額不會被扣除。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - UserDefinedDICT Parsing ERROR. (Please check your the format and encoding.): 使用者自定詞典無法載入,請檢查格式 (Dict) 或編碼 (UTF-8) 是否正確。 | ||
| - Maximum UserDefinedDICT file size exceeded! (UserDefinedDICT file shall be samller than 10MB.): 使用者自定詞典檔案大小超過 10MB。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| result_pos | list | 列表中含有每一句各自分開的斷詞結果,詞組前後另外加上了詞性標記 (Part-Of-Speech)。 |
| result_obj | list | 列表中含有每一句各自分開的斷詞物件結果,包含詞組與詞性標記(Part-Of-Speech)。 |
| result_segmentation | str | 完整的輸入文句已經斷詞處理並以斜線 ( / ) 標出詞彙斷點。回傳時以字串回傳。 |
| exec_time | float | 本次斷詞作業耗費的伺服器時間。 |
| version | str | 本次斷詞作業所使用的演算法版本。 |
| level | str | 本次斷詞作業所使用的知識能力等級。 |
| word_count_balance | int | 您帳號下剩餘可用的字數值。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "我想過過過兒過過的日子。",
"placeholder": "我想過過過兒過過的日子。",
"required": true
},
{
"type": "text",
"key": "version",
"value": "latest",
"placeholder": "latest",
"required": false
},
{
"type": "select",
"key": "level",
"value": "lv2",
"candidate": ["lv1", "lv2", "lv3"],
"multiple": false,
"required": false
},
{
"type": "dict",
"key": "user_defined_dict_file",
"value": {},
"placeholder": {"key": ["value1", "value2"]},
"required": false
},
{
"type": "text",
"key": "time_ref",
"value": "2023-09-06 00:00:00",
"placeholder": "yyyy-mm-dd HH:MM:SS",
"required": false
},
{
"type": "select",
"key": "pinyin",
"value": "BOPOMOFO",
"candidate": ["BOPOMOFO", "HANYU"],
"required": false
},
{
"type": "bool",
"key": "opendata_place",
"value": false,
"required": false
},
{
"type": "bool",
"key": "wikidata",
"value": false,
"required": false
},
{
"type": "bool",
"key": "chemical",
"value": true,
"required": false
},
{
"type": "bool",
"key": "emoji",
"value": true,
"required": false
}
]
}
取得目前所有版本
HTTP Request
POST https://api.droidtown.co/Articut/Versions/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Articut Docker 版本無需設定此參數。 |
| api_key | str | "" | 在本站購買斷詞服務額度,完成付費後取得的一個具有 31 字符長度的字串。Articut Docker 版本無需設定此參數。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並取回結果,回傳 True;失敗,則回傳 False |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成斷詞作業。 | ||
| - Authtication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳斷詞結果的情況下,您帳號的餘額不會被扣除。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| versions | dict | 目前可使用的 Articut 版本。 |
| - version: 版本號。 | ||
| - release_date: 釋出日期。 | ||
| - level: 可指定的演算法版本。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Versions/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
}
]
}
使用自定義辭典
因為 Articut 只處理「語言知識」而不處理「百科知識」。
我們提供「使用者自定義」詞彙表的功能,並標記為 <UserDefined> 。
使用 Dictionary 格式,請自行編寫。
HTTP Request
POST https://api.droidtown.co/Articut/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Articut Docker 版本無需設定此參數。 |
| api_key | str | "" | 在本站購買斷詞服務額度,完成付費後取得的一個具有 31 字符長度的字串。Articut Docker 版本無需設定此參數。 |
| input_str | str | "" | 將要送上 Articut 進行斷詞暨詞性標記處理的文字。注意!每次最大長度不得超過 2000 個字符。 |
| user_defined_dict_file | dict | {} | 使用者自定詞典,必須是 dictionary 格式。 (e.g. UserDefinedDICT = {"key": ["value1", "value2",...],...})。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成斷詞作業。 | ||
| - UserDefinedDICT Parsing ERROR. (Please check your the format and encoding.): 使用者自定詞典無法載入,請檢查格式 (Dict) 或編碼 (UTF-8) 是否正確。 | ||
| - Maximum UserDefinedDICT file size exceeded! (UserDefinedDICT file shall be samller than 10MB.): 使用者自定詞典檔案大小超過 10MB。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "我正在計劃地球人類補完計劃",
"placeholder": "我正在計劃地球人類補完計劃",
"required": true
},
{
"type": "dict",
"key": "user_defined_dict_file",
"value": {"地球人類補完計劃": ["人類補完計劃", "補完計劃"]},
"placeholder": {"地球人類補完計劃": ["人類補完計劃", "補完計劃"]},
"required": false
}
]
}
調用觀光資訊資料庫
政府開放平台中存有「交通部觀光局蒐集各政府機關所發佈空間化觀光資訊」。
Articut 可取用其中的資訊,並標記為 <KNOWLEDGE_place>
HTTP Request
POST https://api.droidtown.co/Articut/API/
範例程式
{
"url": "https://api.droidtown.co/Articut/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "雲林的巧克力觀光工廠",
"placeholder": "雲林的巧克力觀光工廠",
"required": true
},
{
"type": "bool",
"key": "opendata_place",
"value": true,
"required": false
}
]
}
詞性標記 (Part-of-speech, POS)
我(ENTITY_pronoun) 終生(ENTITY_nouny) 所(FUNC_inner) 追尋(ACTION_verb) 的(FUNC_inner) 標的(ENTITY_nouny)
只有斷詞結果,無法處理句子的意義,需要 POS 才能進行語意分析與理解。 主要依據詞彙意義對詞進行劃分每個單詞在句子內所扮演的詞性。
標記類別
| 類別 | 標記名稱 |
|---|---|
| 實體類 | ENTITY |
| 動詞類 | ACTION、ASPECT、MODAL、AUX |
| 時間類 | TIME |
| 修飾詞 | IDIOM、MODIFIER、MODIFIER_color、ModifierP、DegreeP、QUANTIFIER |
| 功能詞 | FUNC |
| 句型詞 | CLAUSE |
| NER類 | LOCATION、KNOWLEDGE、UserDefined、RANGE |
實體類 (Entity)
「實詞」是詞類的一種,又稱「名詞」,可以獨立成句。可指代人、物、事、時、地、情感、概念、方位的名詞等實體或抽象事物的詞。
有幾個詞組組合規則如下:
- 連續的 nouny 可以被視為是同一個大名詞組 (e.g., 咖啡(ENTITY_nouny) 杯(ENTITY_nouny) 就直接視為「咖啡杯」(ENTITY_NP)
- 遇到 nounHead 時,會向前疊加成為名詞組。(e.g., 小(MODIFIER) 紅(MODIFIER_color) 帽(ENTITY_nounHead) 會被疊加成為「小紅帽(ENTITY_nouny)」;遊樂(ACTION_verb) 場(ENTITY_nounHead) 會被疊加成「遊樂場」(ENTITY_nouny)
- 相對於前項,nouny 則不會跟動詞 (ACTION_verb) 做疊加成名詞組,只會在擔任動詞的受詞,而成為動詞組。(e.g., 認識(ACTION_verb) 字(ENTITY_nouny) 會變成「認識字」(VerbP)
| 標記名稱 | 說明 |
|---|---|
<ENTITY_num> |
單純數字表示 |
<ENTITY_classifier> |
量詞 (或中文系稱的「分類詞」) |
<ENTITY_measurement> |
量測詞 (表示是一個測量值。例如「一公斤」、「30公分」…等) |
<ENTITY_person> |
名詞,且系統推測應該指某個「人類」。(以漢人常見三字名、單名為主) |
<ENTITY_pronoun> |
代名詞。 (若有需要,可再細分「專指代名詞」(e.g., 爸爸) 或「泛指代名詞」(e.g., 老公公)) |
<ENTITY_possessive> |
所有格名詞。 |
<ENTITY_noun> |
系統已認得的名詞。 |
<ENTITY_nounHead> |
名詞組的中心語。 |
<ENTITY_nouny> |
系統推測應該是名詞。 |
<ENTITY_oov> |
系統不知道是什麼,但把它當名詞用。 |
<ENTITY_DetPhrase> |
限定詞詞組,由一個「限定詞 (這、那)」和一個「量詞 (一部,兩台)」組成。 e.g., <ENTITY_DetPhrase>這一台</ENTITY_DetPhrase> |
動詞類 (Verb)
「動詞」用來表示動作、發生或是存在的狀態,可以單獨存在或與不同的修飾詞、助詞和主詞組成句子。
| 標記名稱 | 說明 |
|---|---|
<ACTION_lightVerb> |
輕動詞 (e.g., 被、把、弄…) |
<ACTION_verb> |
動詞 |
<ACTION_eventQuantifier> |
動作量詞,長得很像名詞的量詞。 e.g., 一部、兩台 它的測量目標是「動作的次數」,而不是「名詞的數量」。 e.g., 跑 <ACTION_eventQuantifier>一趟</ACTION_eventQuantifier> |
<ACTION_quantifiedVerb> |
量化動詞,表示該動作只做了一定程度的量。 e.g., 看一看、瞧瞧、嚐嚐看…等 |
<VerbP> |
動詞組,指的是一個動詞 (Verb)加上時態 (ASPECT)或受詞 (ENTITY)的動詞。 e.g., |
<ACTION\_verb>讀</ACTION\_verb><ENTITY\_DetPhrase>這本</ENTITY\_DetPhrase><ENTITY\_noun>書</ENTITY\_noun> |
|
<VerbP>讀過</VerbP><ENTITY\_DetPhrase>這本</ENTITY\_DetPhrase><ENTITY\_noun>書</ENTITY\_noun> |
|
<ASPECT> |
時態標記 (了、著…等) |
<AUX> |
助動詞 (e.g., 是、為…) |
<MODAL> |
情態標記詞 (e.g., 可以、能、會…) |
時間類 (Time)
與時間相關的詞彙,包含相對時間、絕對時間與中文傳統的時間單位。
| 標記名稱 | 說明 |
|---|---|
<TIME_holiday> |
和節日相關的時間。 |
<TIME_justtime> |
和現在或瞬時相關的時間。 |
<TIME_day> |
和以「天」為單位相關的時間。 |
<TIME_week> |
和以「週」為單位相關的時間。 |
<TIME_month> |
和以「月」為單位相關的時間。 |
<TIME_season> |
和以「季」為單位相關的時間。 |
<TIME_year> |
和以「年」為單位相關的時間。 |
<TIME_decade> |
和以「比年還要長的時間」為單位相關的時間。 |
修飾詞 (Modifier)
用來修飾句子,使句子所要表達的意思更豐富、完整。
| 標記名稱 | 說明 |
|---|---|
<DegreeP> |
程度詞詞組:由一個「形容詞」加上一個「程度中心語 (e.g.,很、非常…)」組成。 e.g., <DegreeP>很明顯</DegreeP> |
<IDIOM> |
成語或諺語。 |
<MODIFIER> |
形容詞及副詞。 |
<MODIFIER_color> |
顏色形容詞。 |
<ModifierP> |
形容詞或副詞詞組。由一個「形容詞/副詞」加上一「…地」組成。 e.g., <ModifierP>明顯地</ModifierP> |
<QUANTIFIER> |
量化詞標記 (都、全…等) |
功能詞 (Function Word)
指的是中文詞彙中沒有實際意義的詞,且無法獨立成句。
例如:介詞、連接詞、助詞…等。
| 標記名稱 | 說明 |
|---|---|
<FUNC_conjunction> |
連接功能詞 |
<FUNC_degreeHead> |
形容詞組的程度中心語(很、極、非常…等)。表示形容詞到這裡就不會再疊加了。其旁邊形容詞會和此程度中心語形成一個用來「描述程度」的修飾、形容用語。 |
<FUNC_determiner> |
定冠詞 (或中文系稱的「定語」) |
<FUNC_inner> |
內向功能詞 (完整語意可在本句以內滿足。e.g., 在…) |
<FUNC_inter> |
外向功能詞 (完整語意需在本句以外滿足。e.g., 然而…) |
<FUNC_modifierHead> |
形容詞及副詞組的中心語。 |
<FUNC_negation> |
否定功能詞 |
句型詞 (Clause)
問句類 (wh-問句及 yes-no 問句) 或直述句類。
| 標記名稱 | 說明 |
|---|---|
<CLAUSE_AnotAQ> |
「A-not-A」問句 |
<CLAUSE_YesNoQ> |
「是非」問句 |
<CLAUSE_WhoQ> |
「誰」問句 |
<CLAUSE_WhatQ> |
「物」問句 |
<CLAUSE_WhereQ> |
「何地」問句 |
<CLAUSE_WhenQ> |
「何時」問句 |
<CLAUSE_WhyQ> |
「原因」問句 |
<CLAUSE_HowQ> |
「程度/過程」問句 |
<CLAUSE_particle> |
沒什麼特別意義,就只是一個句子裡的小元素。(e.g., 啊、啦、喔…) |
命名實體類 (Named Entity Recognition, NER)
實體指一個真實世界的物件,可能是地方、人物、組織、產品、抽象或具體的東西等具有專有名稱的物件。
NER 標記可幫助識別文本中具有特定意義的實體 (中文人名、行政地名、其他名詞...等)
| 標記名稱 | 說明 |
|---|---|
<LOCATION> |
地名 |
<RANGE_locality> |
地名範圍標記 |
<RANGE_period> |
時間範圍標記 |
<UserDefined> |
使用者自定義的詞彙 |
<KNOWLEDGE_addTW> |
台灣地址 |
<KNOWLEDGE_currency> |
金錢。例如: <KNOWLEDGE_currency>100美元</KNOWLEDGE_currency> 和 <KNOWLEDGE_currency>100元</KNOWLEDGE_currency><ENTITY_noun>美金</ENTITY_noun> |
<KNOWLEDGE_lawTW> |
法條索引 |
<KNOWLEDGE_place> |
政府開放平台中的觀光景點 |
<KNOWLEDGE_routeTW> |
台灣道路名稱 |
<KNOWLEDGE_url> |
網址 |
<KNOWLEDGE_wikiData> |
WikiData 開放資料 |
<KNOWLEDGE_chemical> |
化學物質 |
進階功能
Articut Addons
可以依需求找出「名詞」、「動詞」或是「形容詞」…等詞彙語意本身已經完整的詞彙。
HTTP Request
POST https://api.droidtown.co/Articut/Addons/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_pos | dict | Articut 斷詞結果標記。 | |
| index_with_pos | bool | True | 計算所擷取的字串位置時,是否包含詞性標記 (POS)。 |
| func | list | ["get_all"] | 可設置為以下參數: |
| - get_all: 取出以下所有參數的結果。 | |||
- get_addtw: 取出斷詞結果中含有 <KNOWLEDGE_addTW> 標籤的台灣地址字串。例如「台北市中山區民權東路二段109號」。 |
|||
- get_chemical: 取出斷詞結果中含有 <KNOWLEDGE_chemical> 標籤的化學物質。每個句子內的化學物質為一個 list。 |
|||
- get_color: 取出斷詞結果中含有 <MODIFIER_color> 標籤的顏色字串。每個句子內的顏色為一個 list。 |
|||
| - get_content_word: 取出斷詞結果中的實詞 (content word)。每個句子內的實詞為一個 list。 | |||
- get_currency: 取出斷詞結果中含有 <KNOWLEDGE_currency> 標籤的貨幣金額字串。每個句子內的貨幣金額為一個 list。 |
|||
- get_currency_greedy: 取出斷詞結果中含有 <KNOWLEDGE_currency> 標籤與 <ENTITY_noun> <ENTITY_num> 組合標籤的貨幣金額字串。每個句子內的貨幣金額為一個 list。 |
|||
| - get_location_stem: 取出斷詞結果中的地理位置 (location)。此處指的是地理位置標記的行政區地名詞彙,例如「台北」、「桃園」、「墨西哥」。每個句子內的地理位置列為一個 list。 | |||
- get_noun_stem: 取出斷詞結果中的名詞 (noun)。此處指的是 ENTITY_noun、ENTITY_nouny、ENTITY_nounHead 或 ENTITY_oov 標記的名詞詞彙。每個句子內的名詞為一個 list。 |
|||
- get_opendata_place: 取出斷詞結果中的景點 (KNOWLEDGE_place)。此處指的是景點 KNOWLEDGE_place 標記的非行政地點名稱詞彙,例如「鹿港老街」、「宜蘭運動公園」。每個句子內的景點為一個 list。 |
|||
| - get_person: 取出斷詞結果中的人名 (person)。每個句子內的人名為一個 list。 | |||
| - get_person_and_pronoun: 取出斷詞結果中的人名 (person) 與代名詞 (pronoun)。每個句子內的人名與代名詞為一個 list。 | |||
- get_question: 取出斷詞結果中含有 <CLAUSE_Q> 標籤的句子。例如「是非問句:你認識他嗎?」 |
|||
| - get_time: 取出斷詞結果中的時間 (time)。每個句子內的時間列為一個 list。 | |||
- get_verb_stem: 取出斷詞結果中的動詞 (verb)。此處指的是 ACTION_verb 標記的動詞詞彙。每個句子內的動詞為一個 list。 |
|||
- get_wikidata: 取出斷詞結果中含有 <KNOWLEDGE_wikiData> 標籤的 Wikidata 標題字串。每個句子內的 Wikidata 標題文字為一個 list。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Addons/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "list",
"key": "result_pos",
"value": [
"<MODIFIER>剛剛</MODIFIER><ACTION_verb>得知</ACTION_verb><KNOWLEDGE_place>435藝文特區</KNOWLEDGE_place><AUX>是</AUX><ENTITY_classifier>個</ENTITY_classifier><ACTION_verb>遛</ACTION_verb><ENTITY_nouny>小孩</ENTITY_nouny><FUNC_inner>的</FUNC_inner><MODIFIER>好</MODIFIER><ENTITY_noun>地方</ENTITY_noun>",
",",
"<ENTITY_pronoun>你</ENTITY_pronoun><CLAUSE_YesNoQ><AUX>是</AUX><FUNC_negation>否</FUNC_negation></CLAUSE_YesNoQ><ACTION_verb>知道</ACTION_verb><TIME_day>傍晚</TIME_day><MODAL>可以</MODAL><ACTION_verb>到</ACTION_verb><KNOWLEDGE_place>觀音亭</KNOWLEDGE_place><ACTION_verb>去</ACTION_verb><ACTION_verb>看</ACTION_verb><ENTITY_nouny>夕陽</ENTITY_nouny><CLAUSE_particle>喔</CLAUSE_particle>",
"!",
"<TIME_day>今日</TIME_day><TIME_day>傍晚</TIME_day><FUNC_inner>在</FUNC_inner><LOCATION>新竹市</LOCATION><LOCATION>北區</LOCATION><ACTION_verb>溜</ACTION_verb><ENTITY_nouny>小狗</ENTITY_nouny>",
"。"
],
"placeholder": [
"<POS>TEXT</POS>","<POS>TEXT</POS>"
],
"required": true
},
{
"type": "select",
"key": "func",
"value": "get_all",
"candidate": [
"get_all","get_addtw","get_chemical","get_color","get_content_word","get_currency","get_currency_greedy",
"get_location_stem","get_noun_stem","get_opendata_place","get_person","get_person_and_pronoun","get_question",
"get_time","get_verb_stem","get_wikidata"
],
"multiple": true,
"required": true
},
{
"type": "bool",
"key": "index_with_pos",
"value": true,
"required": false
}
]
}
NER
命名實體標記 (Named Entity Recognition, NER) 是許多 NLP 高階應用中會使用到的標記。Articut 原生支援數十種命名實體的辨識。為了方便理解與利用,以下列出其標記以及說明。 微軟亞洲研究院 (Microsoft Research Lab Asia, MSRA) 提出有 26 種命名實體標記 (Named Entity Recognition, NER) 和 Articut 對照表,請參考 Articut API
HTTP Request
POST https://api.droidtown.co/Articut/Toolkit/NER/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_pos | dict | Articut 斷詞結果標記。 | |
| index_with_pos | bool | True | 計算所擷取的字串位置時,是否包含詞性標記 (POS)。 |
| func | list | ["get_all"] | 可設置為以下參數: |
| - get_addtw: 在 KNOWLEDGE_addTW 裡的即為台灣地址字串。 | |||
| - get_age: 一個 num 再加一個 ENTITY 歲。 | |||
| - get_area: 一個 ENTITY 後有 RANGE_locality 表示前面的 ENTITY 空間的上下左右內外附近。 | |||
| - get_date: 一個 month 再加一個 day。 | |||
| - get_decimal: 內含小數點的 num。 | |||
| - get_duration: 可能為 justtime/day/week/month/season/year/decade,視時間長度而定。 | |||
| - get_emoji: 取得文本中的 emoji 符號。 | |||
| - get_food: 取得文本中的食物名稱。 | |||
| - get_food_with_location: 取得文本中的食物名稱連食物前的地方特色詞一起取得。 | |||
| - get_integer: 在 num 裡,可兼容小數點、計位點和中文/阿拉伯數字夾雜及空格。 | |||
| - get_location: 在 LOCATION 裡的即為地點。 | |||
| - get_money: 在 currency 裡的都是金額。 | |||
- get_money_greedy: 都是金額取出斷詞結果中含有 <KNOWLEDGE_currency> 標籤與 <ENTITY_noun> <ENTITY_num> 組合標籤的貨幣金額字串。每個句子內的貨幣金額為一個 list。 |
|||
| - get_ordinal: 在 DetPhrase 中有「第」。 | |||
| - get_person: 在 person 裡的即為人名。 | |||
| - get_person_and_pronoun: 取得 person 人名與 pronoun 中的代名詞。 | |||
| - get_time: 在 TIME_ 的分類下有超過年的時間/年/季/月/週/日/短於一日的時間/假日。 | |||
| - get_angle: 在 measurement 裡有「度」。 | |||
| - get_capactity: 在 measurement 裡有「公升」或其它容量單位。 | |||
| - get_fraction: 在 measurement 裡有「分之」。 | |||
| - get_frequency: 在 measurement 裡有「赫茲」這類頻率單位。 | |||
| - get_measure: 在 measurement 裡的都是測量值。 | |||
| - get_length: 在 measurement 裡有「公分」這類長度單位。 | |||
| - get_percent: 在 measurement 中有「百分之」。 | |||
| - get_rate: 在 measurement 中有「倍」。 | |||
| - get_speed: 在 measurement 中有速度單位,或是 measurement 後跟著時間。 | |||
| - get_temperature: 在 measurement 中有溫度單位。 | |||
| - get_weight: 在 measurement 中有重量單位。 | |||
| - get_www: 在 KNOWLEDGE_url 中的即為網址。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Toolkit/NER/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "list",
"key": "result_pos",
"value": [
"<FUNC_inter>其實</FUNC_inter><TIME_day>早</TIME_day><FUNC_inner>在</FUNC_inner><TIME_month>五月</TIME_month><TIME_day>15日</TIME_day><ACTION_verb>開始</ACTION_verb><ACTION_verb>突破</ACTION_verb><ENTITY_classifier>百例</ENTITY_classifier><TIME_justtime>之前</TIME_justtime>",
",",
"<ENTITY_DetPhrase>這起</ENTITY_DetPhrase><ENTITY_noun>社區</ENTITY_noun><MODIFIER>大</MODIFIER><ACTION_verb>爆發</ACTION_verb><ENTITY_nouny>疫情</ENTITY_nouny><FUNC_inner>就</FUNC_inner><ASPECT>已經</ASPECT><ACTION_verb>有</ACTION_verb><ENTITY_classifier>一些</ENTITY_classifier><VerbP>端倪</VerbP>",
"。",
"<TIME_week>上星期</TIME_week><ENTITY_pronoun>我們</ENTITY_pronoun><ACTION_verb>約</ACTION_verb><FUNC_degreeHead>好</FUNC_degreeHead><ASPECT>了</ASPECT>",
",",
"<ENTITY_DetPhrase>這件</ENTITY_DetPhrase><ENTITY_nouny>事情</ENTITY_nouny><TIME_day>今天</TIME_day><TIME_day>下午</TIME_day><TIME_justtime>六點</TIME_justtime><AUX>到</AUX><TIME_justtime>八點</TIME_justtime><ACTION_verb>要</ACTION_verb><ACTION_verb>討論</ACTION_verb>",
"。",
"《",
"<ENTITY_nouny>小糧倉</ENTITY_nouny>",
"》",
"<ENTITY_oov>菜單</ENTITY_oov><ACTION_verb>販售</ACTION_verb><ENTITY_nounHead>品項</ENTITY_nounHead><TIME_justtime>十分</TIME_justtime><MODIFIER>多元</MODIFIER>",
",",
"<ENTITY_oov>雞</ENTITY_oov><MODIFIER_color>白</MODIFIER_color><ENTITY_nounHead>湯拉麵</ENTITY_nounHead>",
"、",
"<ENTITY_oov>咖哩飯</ENTITY_oov>",
"、",
"<ENTITY_oov>鐵板漢堡</ENTITY_oov><ACTION_verb>排定</ACTION_verb><ENTITY_nouny>食</ENTITY_nouny><ACTION_verb>等</ACTION_verb>",
"。"
],
"placeholder": [
"<POS>TEXT</POS>","<POS>TEXT</POS>"
],
"required": true
},
{
"type": "select",
"key": "func",
"value": "get_all",
"candidate": [
"get_all","get_addtw","get_age","get_area","get_date","get_decimal","get_duration","get_emoji","get_food",
"get_food_with_location","get_integer","get_location","get_money","get_money_greedy","get_ordinal","get_person",
"get_person_and_pronoun","get_time","get_angle","get_capactity","get_fraction","get_frequency","get_measure",
"get_length","get_percent","get_rate","get_speed","get_temperature","get_weight","get_www"
],
"multiple": true,
"required": true
}
]
}
法律檢索工具
HTTP Request
POST https://api.droidtown.co/Articut/Toolkit/Laws/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_pos | dict | Articut 斷詞結果標記。 | |
| func | list | ["get_all"] | 可設置為以下參數: |
| - get_all: 取出以下所有參數的結果。 | |||
- get_law_article: 取出斷詞結果中含有 <KNOWLEDGE_lawTW> 標籤的法條索引。 |
|||
| - get_crime: 取出斷詞結果中的犯罪罪名。 | |||
| - get_criminal_responsibility: 取出斷詞結果中的判決刑責。 | |||
| - get_event_ref: 取出斷詞結果中的事件參照。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Toolkit/Laws/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "list",
"key": "result_pos",
"value": [
"<ENTITY_nouny>被告</ENTITY_nouny><MODIFIER>前</MODIFIER><FUNC_inter>因</FUNC_inter><MODIFIER>非法</MODIFIER><ACTION_verb>持有</ACTION_verb><ENTITY_nouny>槍械</ENTITY_nouny>",
",",
"<CLAUSE_particle>業</CLAUSE_particle><ACTION_verb>經</ACTION_verb><ENTITY_nouny>前案</ENTITY_nouny><ACTION_verb>判決</ACTION_verb><MODIFIER>非法</MODIFIER><ACTION_verb>持有</ACTION_verb><MODAL>可</MODAL><ACTION_verb>發射</ACTION_verb><ENTITY_nouny>子彈</ENTITY_nouny><ENTITY_nouny>具</ENTITY_nouny><ENTITY_nouny>殺傷力</ENTITY_nouny><FUNC_inner>之</FUNC_inner><ENTITY_nouny>槍枝</ENTITY_nouny><ENTITY_nouny>罪</ENTITY_nouny>",
",",
"<ACTION_verb>處</ACTION_verb><MODIFIER>有期</MODIFIER><ENTITY_nounHead>徒刑</ENTITY_nounHead><TIME_year>參年</TIME_year><TIME_month>陸月</TIME_month>",
",",
"<ACTION_verb>併</ACTION_verb><ENTITY_nounHead>科罰金</ENTITY_nounHead><ENTITY_noun>新臺幣</ENTITY_noun><KNOWLEDGE_currency>拾萬元</KNOWLEDGE_currency>",
"。",
"<FUNC_inner>於</FUNC_inner><ENTITY_nouny>前案</ENTITY_nouny><ACTION_verb>偵查</ACTION_verb><ENTITY_noun>過程</ENTITY_noun><RANGE_locality>中</RANGE_locality>",
",",
"<ENTITY_nouny>南投縣</ENTITY_nouny><ENTITY_noun>政府</ENTITY_noun><ENTITY_nouny>警察局</ENTITY_nouny><LOCATION>集集</LOCATION><ENTITY_oov>分局</ENTITY_oov><FUNC_inner>之</FUNC_inner><ENTITY_nouny>員警</ENTITY_nouny>",
",",
"<ACTION_verb>持</ACTION_verb><ENTITY_nouny>本院</ENTITY_nouny><ACTION_verb>核發</ACTION_verb><FUNC_inner>之</FUNC_inner><TIME_year>105年度</TIME_year><ENTITY_oov>聲</ENTITY_oov><VerbP>搜字</VerbP><KNOWLEDGE_lawTW>第165號</KNOWLEDGE_lawTW><ACTION_verb>搜索</ACTION_verb><ENTITY_nouny>票</ENTITY_nouny><ACTION_verb>搜索</ACTION_verb>",
"。"
],
"placeholder": [
"<POS>TEXT</POS>","<POS>TEXT</POS>"
],
"required": true
},
{
"type": "select",
"key": "func",
"value": "get_all",
"candidate": [
"get_all","get_law_article","get_crime","get_criminal_responsibility","get_event_ref"
],
"multiple": true,
"required": true
}
]
}
LocalRE
台灣 中文地址 資訊擷取工具
HTTP Request
POST https://api.droidtown.co/Articut/Toolkit/LocalRE/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_pos | dict | Articut 斷詞結果標記。 | |
| index_with_pos | bool | True | 計算所擷取的字串位置時,是否包含詞性標記 (POS)。 |
| func | list | ["get_all"] | 可設置為以下參數: |
| - get_all: 取出以下所有參數的結果。 | |||
| - get_county: 取出是哪個「縣」。 | |||
| - get_city: 取出是哪個「市」。 | |||
| - get_district: 取出是哪個「區」。 | |||
| - get_township: 取出是哪個「鄉」或「里」。 | |||
| - get_town: 取出是哪個「鎮」。 | |||
| - get_village: 取出是哪個「村」。 | |||
| - get_neighborhood: 取出是哪個「鄰」。 | |||
| - get_road: 取出是哪條「路」。 | |||
| - get_section: 取出是哪一「段」。 | |||
| - get_alley: 取出是哪一「巷弄」。 | |||
| - get_number: 取出是幾「號」。 | |||
| - get_floor: 取出是幾「樓」。 | |||
| - get_room: 取出「室」的編號。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Toolkit/LocalRE/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "list",
"key": "result_pos",
"value": [
"<MODIFIER>滿</MODIFIER><MODIFIER>堂紅</MODIFIER><ENTITY_nouny>麻辣鍋</ENTITY_nouny>",
"!",
"<ENTITY_oov>地址</ENTITY_oov>",
":",
"<KNOWLEDGE_addTW>台中市西區台灣大道二段459號14樓</KNOWLEDGE_addTW>"
],
"placeholder": [
"<POS>TEXT</POS>","<POS>TEXT</POS>"
],
"required": true
},
{
"type": "select",
"key": "func",
"value": "get_all",
"candidate": [
"get_all","get_county","get_city","get_district","get_township","get_town","get_village",
"get_neighborhood","get_road","get_section","get_alley","get_number","get_floor","get_room"
],
"multiple": true,
"required": true
}
]
}
TF-IDF
基於 TF-IDF 算法的關鍵詞抽取
HTTP Request
POST https://api.droidtown.co/Articut/Toolkit/TFIDF/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_segmentation | str | Articut 斷詞結果,提取關鍵詞的文本。 | |
| top_k | int | 20 | 提取幾個 TF-IDF 的關鍵詞。 |
| with_weight | bool | False | 為是否返回關鍵詞權重值。 |
| allow_pos | list | 預設為空值,亦即全部抽取。抽取指定詞性。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Toolkit/TFIDF/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "text",
"key": "result_segmentation",
"value": "沒有/人/可以/決定/你/的/命運/,/命運/在/自己/的/手/上/。",
"placeholder": "沒有/人/可以/決定/你/的/命運/,/命運/在/自己/的/手/上/。",
"required": true
},
{
"type": "int",
"key": "top_k",
"value": 10,
"placeholder": 10,
"required": true
},
{
"type": "bool",
"key": "with_weight",
"value": true,
"required": true
},
{
"type": "list",
"key": "allow_pos",
"value": [],
"placeholder": [],
"required": false
}
]
}
TextRank
基於 TextRank 算法的關鍵詞抽取
將待抽取關鍵詞的文本斷詞。 以固定的窗格大小 (預設值為 5,通過 span 屬性調整),詞之間的共現關係,建構出不帶權圖。 計算途中節點的 PageRank。 算法論文:TextRank: Bringing Order into Texts
HTTP Request
POST https://api.droidtown.co/Articut/Toolkit/TextRank/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| result_pos | list | Articut 斷詞結果標記,提取關鍵詞的文本。 | |
| top_k | int | 10 | 提取幾個關鍵詞。 |
| with_weight | bool | False | 為是否返回關鍵詞權重值。 |
| allow_pos | list | 預設為空值,亦即全部抽取。抽取指定詞性。 |
範例程式
{
"url": "https://api.droidtown.co/Articut/Toolkit/TextRank/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。",
"required": true
},
{
"type": "list",
"key": "result_pos",
"value": [
"<FUNC_negation>沒有</FUNC_negation><ENTITY_nouny>人</ENTITY_nouny><MODAL>可以</MODAL><ACTION_verb>決定</ACTION_verb><ENTITY_pronoun>你</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ENTITY_nouny>命運</ENTITY_nouny>",
",",
"<ENTITY_oov>命運</ENTITY_oov><FUNC_inner>在</FUNC_inner><ENTITY_pronoun>自己</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ENTITY_nouny>手</ENTITY_nouny><RANGE_locality>上</RANGE_locality>",
"。"
],
"placeholder": [
"<POS>TEXT</POS>","<POS>TEXT</POS>"
],
"required": true
},
{
"type": "int",
"key": "top_k",
"value": 10,
"placeholder": 10,
"required": true
},
{
"type": "bool",
"key": "with_weight",
"value": true,
"required": true
},
{
"type": "list",
"key": "allow_pos",
"value": [],
"placeholder": [],
"required": false
}
]
}
KeyMoji
KeyMoji 服務介紹
KeyMoji 關鍵情緒偵測 (SENSE2、SENSE8、Tension) 採用不同於其它「素人標記」和「純機器學習」的文本情緒偵測分析工具,結合了「句型」、「邏輯語意」和「詞彙模型」,設計出一個完整的「情緒計算過程」。 並依中文的句法結構,定義了幾種句型:
- 正向表述句型 > 川普終於輸了! (e.g., X 終於 Y 了!)
- 負向表述句型 > 你是有天才嗎? (e.g., X 是有 Y 嗎?)
- 趨中性句型 > 我只是要他開心一點 (e.g., X 只是要 Y )
- 反轉極性句型 > 你不是有個富爸爸 (e.g., X 不是有 Y )
- ...
此外,KeyMoji 同時整合了「句法知識」和「詞彙模型」,將 Rule-based 和 Data-driven 兩種方法 Hybrid 在一起。
Emotions in Formula
情緒的組成是由:詞彙 + 句型 + 語境 + 個人習慣 構成。
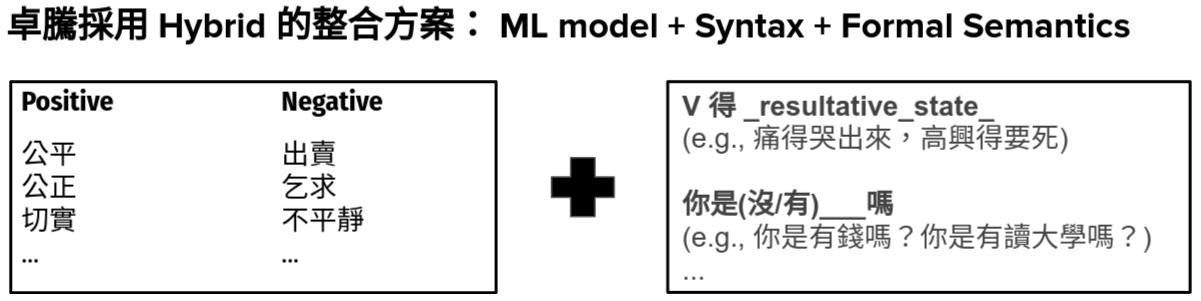
KeyMoji 透過「句型」+「詞彙模型」的混合式演算法,將每一句的情緒偵測結果投射到二維 (SENSE2) 及八維 (SENSE8) 的情緒空間裡。另將「句型」本身的權重效果獨立成「情緒張力」(Tension) 的結果。
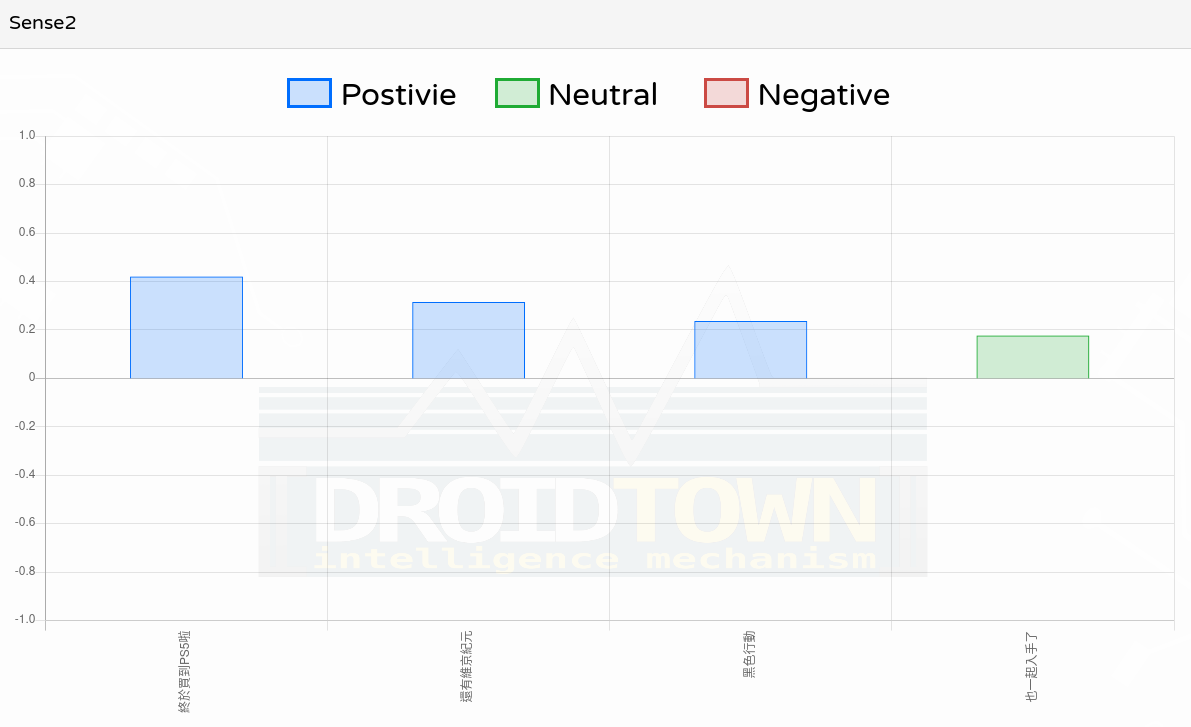
Context Sensitivity (語境敏感功能)
KeyMoji 有 Context_Sensitivity (語境敏感開關) 的設計。 如果前幾句是「正向描述」而這一句是「中性描述」的話,那麼這個「中性描述」也會被前文裡「正向描述」的情緒延續,使分數拉高一點。這麼一來,就能呈現「因前後文的語境」帶出的正負向情緒計算了。
舉個例子:
「終於買到 PS5 啦!」(正向描述) 「還有維京紀元」(中性描述,被前文帶出正向) 「黑色行動」(中性描述,被前文帶出正向) 「也一起入手了」(中性描述,被前文帶趨近正向)
Scoping
在語言裡還有一個叫 "Scope" 的概念,它是用來計算某些語意的控制範圍的 比如說「每個」和「某個」都是屬於帶有 "Scope" 的運算子 (operator)。那麼,以這個句子為例:
- 遊戲裡的每個玩家都選擇某個角色
- 當「每個」的 scope 大於「某個」的時候,每個玩家扮演的是
不同的角色 - 當「某個」的 scope 大於「每個」的時候,每個玩家扮演的是
同一個角色
- 當「每個」的 scope 大於「某個」的時候,每個玩家扮演的是
簡單地說,這些含有 "socping" 語意功能的詞彙,會影響句子語意的計算結果。而我們已經知道像是「每個」、「都」、「不」、「沒有」…這些詞彙都是帶有 "scoping" 語意功能的詞彙。因此在 KeyMoji 裡,我們也加入了計算 Operator 的 "Scope" 的處理。如下圖:

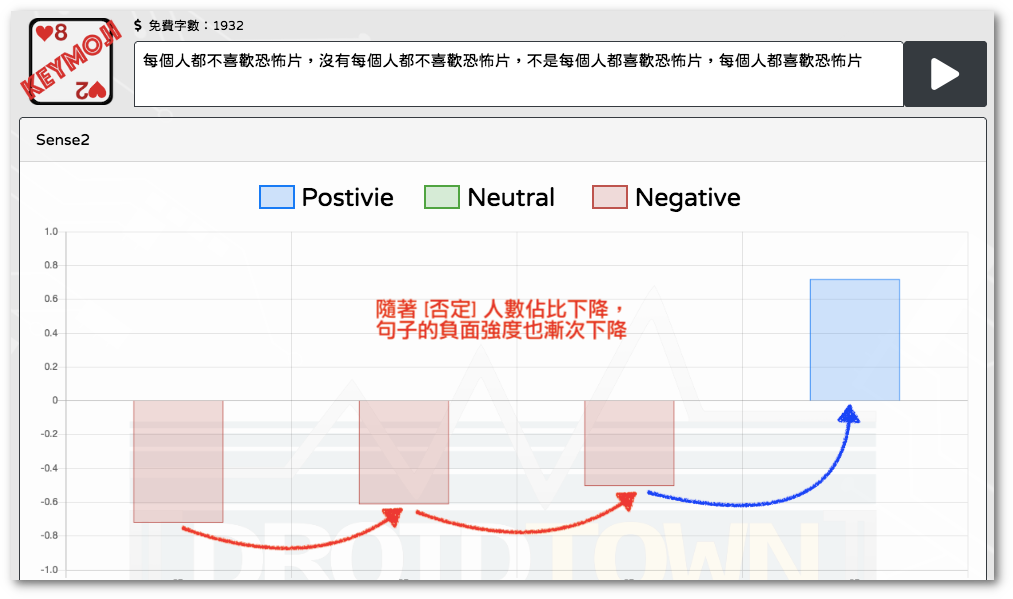
KeyMoji 在設計時,涉及了許多語言學典範轉移以後,對人類認知系統的許多理解的計算公式,然後利用形式語意學裡計算 Scope 的方法,最後再加上詞彙自帶的正負面表示,綜合起來得到的情緒正負面計算結果。
SENSE2
HTTP Request
POST https://api.droidtown.co/KeyMoji/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| input_str | str | "" | KeyMoji 情緒偵測處理的文字。注意!每次最大長度不得超過 6000 個字符。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。此範例為 sense2。 |
| model | str | "general" | 可為 "general"、"hotel"、"restaurant" 或 "shopping",預設為 "general"。指定不同的計算模型,將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間。此功能不會影響 "Tension" 的結果 |
--general: 使用通用模型,依據 句型結構 計算文本的情緒分數。 |
|||
--hotel: 使用旅館評價模型,依據 訓練模型 計算文本的情緒分數。 |
|||
--restaurant: 使用餐廳評價模型,依據 訓練模型 計算文本的情緒分數。 |
|||
--shopping: 使用購物評價模型,依據 訓練模型 計算文本的情緒分數。 |
|||
| context_sensitivity | bool | True | 語境敏感開關,預設為 True。此參數為 True 時,前句的句子若有分數,若此句計算的結果無分數,則前句的分數會延續影響此句分數,直到下一句計算的結果有分數。例如:context_sensitivity = True,input_str = "好不容易離開思念的軌跡,回憶將我聯繫到過去",結果為:"好不容易離開思念的軌跡" => -0.6043, "回憶將我聯繫到過去" => -0.4532;反之,參數為 False 時,"回憶將我聯繫到過去" => 0。將 model 指定為 "general" 時才有此功能。 |
| user_defined | dict | {} | 使用者自訂的正向 "positive"、負向 "negative" 與 "cursing" 字典,若使用此功能,會優先計算其字典內的詞彙分數。例如:{"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。若 positive 與 negative 有相同詞彙,則會相互抵銷其分數。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
| - Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - request['context_sensitivity'] only takes True/False.: context_sensitivity 只能是 boolean 格式。 | ||
| - request['sense'] should be set as 'tension', 'sense2' or 'sense8', other settings don't make any sense to KeyMoji.: sense 需要指定其參數為 'tension', 'sense2' 或 'sense8' 字串。 | ||
| - request['model'] must be one of the models listed: 'general', 'hotel', 'shopping' or 'restaurant'.: model 需要指定其參數為 'general', 'hotel', 'shopping' 或 'restaurant' 字串。 | ||
| - request['user_defined'] Parsing ERROR. (Please check your the format and encoding.): user_defined 必須是 DICT 格式,例如: {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。 | ||
| - Internal Server Error. (System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 sense2。 |
| model | str | 此次情緒偵測所使用的模型。此範例為 general。 |
| results | list | 以句子為一個單位,將計算結果存儲至 dict,內容包含以下 |
| - input_str: 單句的文字字串。 | ||
- cursing: input_str 是否含有國罵的文字內容,例:XX娘。 |
||
- score: 計算 input_str 的情緒分數。若context_sensitivity == True時,會受到前句的結果影響,不同於單句計算的分數。 |
||
- sentiment: 依據語意計算結果判斷 input_str 的表述,屬於在人類情緒光譜上哪個分佈位置: |
||
--positive: 正向表述 (0.2, 1] |
||
--negative: 負向表述 [-1, -0.2) |
||
--neutral: 中性表述 [-0.2, -0.2] |
範例程式
{
"url": "https://api.droidtown.co/KeyMoji/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "高興的要死。",
"placeholder": "高興的要死。",
"required": true
},
{
"type": "text",
"key": "sense",
"value": "sense2",
"placeholder": "sense2",
"required": true
},
{
"type": "select",
"key": "model",
"value": "lv2",
"candidate": ["general", "hotel", "restaurant", "shopping"],
"multiple": false,
"required": false
},
{
"type": "dict",
"key": "user_defined",
"value": {"positive": [], "negative": [], "cursing": []},
"placeholder": {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} ,
"required": false
},
{
"type": "bool",
"key": "context_sensitivity",
"value": true,
"required": false
}
]
}
SENSE8
情緒又稱「情感」,是動物出於本能與生俱來的多種感覺、思想和行為綜合產生的心理和生理狀態,並與我們生活息息相關。有些複雜情緒必須經過與他人互動才能學習到,因此每個人所擁有的情緒數量和對情緒的定義都不一樣。
KeyMoji 依據美國心理學家 Robert Plutchik 提出八種主要的成對兩極核心情緒,分別為 Anger、Anticipation、Disgust、Fear、Joy、Sadness、Surprise、Trust 來做計算。

HTTP Request
POST https://api.droidtown.co/KeyMoji/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| input_str | str | "" | 將要送上 KeyMoji 情緒偵測處理的文字。注意!每次最大長度不得超過 6000 個字符。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。此範例為 sense8。 |
| model | str | "general" | 可為 "general"、"hotel"、"restaurant" 或 "shopping",預設為 "general"。指定不同的計算模型,將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間。此功能不會影響 "Tension" 的結果 |
| user_defined | dict | {} | 使用者自訂的正向 "positive"、負向 "negative" 與 "cursing" 字典,若使用此功能,會優先計算其字典內的詞彙分數。例如:{"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。若 positive 與 negative 有相同詞彙,則會相互抵銷其分數。 |
PS.關於SENSE8八個維度參考的來源。
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
| - Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - request['context_sensitivity'] only takes True/False.: context_sensitivity 只能是 boolean 格式。 | ||
| - request['sense'] should be set as 'tension', 'sense2' or 'sense8', other settings don't make any sense to KeyMoji.: sense 需要指定其參數為 'tension', 'sense2' 或 'sense8' 字串。 | ||
| - request['model'] must be one of the models listed: 'general', 'hotel', 'shopping' or 'restaurant'.: model 需要指定其參數為 'general', 'hotel', 'shopping' 或 'restaurant' 字串。 | ||
| - request['user_defined'] Parsing ERROR. (Please check your the format and encoding.): user_defined 必須是 DICT 格式,例如: {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。 | ||
| - Internal Server Error. (System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 sense8。 |
| model | str | 此次情緒偵測所使用的模型。此範例為 general。 |
| results | list | 以句子為一個單位,將計算結果存儲至 dict,內容包含四種 正/負向情緒,共八種情緒分數[0, 12.5] |
| - input_str: 單句的文字字串。 | ||
| - Anger: 負向情緒分數,在 input_str 裡存在「憤怒」語意意涵的指數。 | ||
| - Disgust: 負向情緒分數,在 input_str 裡存在「噁心」語意意涵的指數。 | ||
| - Fear: 負向情緒分數,在 input_str 裡存在「恐懼」語意意涵的指數。 | ||
| - Sadness: 負向情緒分數,在 input_str 裡存在「悲傷」語意意涵的指數。 | ||
| - Joy: 正向情緒分數,在 input_str 裡存在「歡樂」語意意涵的指數。 | ||
| - Anticipation: 正向情緒分數,在 input_str 裡存在「期待」語意意涵的指數。 | ||
| - Surprise: 正向情緒分數,在 input_str 裡存在「驚喜」語意意涵的指數。 | ||
| - Trust: 正向情緒分數,在 input_str 裡存在「信任」語意意涵的指數。 |
PS.八維度核心情緒分類請參考下表:

範例程式
{
"url": "https://api.droidtown.co/KeyMoji/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "高興的要死。",
"placeholder": "高興的要死。",
"required": true
},
{
"type": "text",
"key": "sense",
"value": "sense8",
"placeholder": "sense8",
"required": true
},
{
"type": "select",
"key": "model",
"value": "lv2",
"candidate": ["general", "hotel", "restaurant", "shopping"],
"multiple": false,
"required": false
},
{
"type": "dict",
"key": "user_defined",
"value": {"positive": [], "negative": [], "cursing": []},
"placeholder": {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} ,
"required": false
},
{
"type": "bool",
"key": "context_sensitivity",
"value": true,
"required": false
}
]
}
Tension
在文章中修飾用詞「形容詞、副詞 MODIFIER」、「成語、諺語 IDIOM」 與「程度中心語 DegreeHead (e.g., 很、非常)」能提高整個句子的情緒張力 Tension。
KeyMoji 利用 Articut 斷詞後的 POS,取出每 180 個字符裡修飾用詞數除以句子的詞彙數 WordCount。試圖呈現文章中「平滑化後,每 180 個字符所呈現的情緒張力」係數。
情緒張力公式

HTTP Request
POST https://api.droidtown.co/KeyMoji/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| input_str | str | "" | 將要送上 KeyMoji 情緒偵測處理的文字。注意!每次最大長度不得超過 6000 個字符。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。此範例為 tension。 |
| user_defined | dict | {} | 使用者自訂的正向 "positive"、負向 "negative" 與 "cursing" 字典,若使用此功能,會優先計算其字典內的詞彙分數。例如:{"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
| - Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - request['sense'] should be set as 'tension', 'sense2' or 'sense8', other settings don't make any sense to KeyMoji.: sense 需要指定其參數為 'tension', 'sense2' 或 'sense8' 字串。 | ||
| - request['user_defined'] Parsing ERROR. (Please check your the format and encoding.): user_defined 必須是 DICT 格式,例如: {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} 。 | ||
| - Internal Server Error. (System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 Tension。 |
| results | list | 以 180 個字符為一個單位,將計算結果存儲至 list,分數區間為 [0, 1]。 |
範例程式
{
"url": "https://api.droidtown.co/KeyMoji/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "texts",
"key": "input_str",
"value": [
"我想向各位更新我們的努力成果,曝光在那荒謬、漫長的11月3日選舉中所發生的大面積選舉舞弊和各種不正常的現象。",
"我們以前有所謂的「選舉日」,現在卻拖延成好幾個選舉週、選舉月,這段時間裡許多不好的事發生了,特別是我們得去證明那些原本我們不需要去驗證的事,才得以執行我們最偉大的特權——選舉權。",
"作為總統,我責無旁貸,保護這個國家的法律和憲法,所以我決心保障我們的選舉系統。",
"而這個系統正遭受合謀攻擊。在總統選舉前的幾個月,我們被多次警告,不要過早宣告我們的勝選;我們反覆被告知,這場選舉將耗時幾週甚至幾個月來分出勝、來數缺席者選票,並確認結果。",
"我的對手被告知:「可以與選舉保持距離,不需要競選活動。我們不需要你。我們搞定了,這場選舉已經結束。」",
"實際上,他們的表現得好像他們早已知道了這場選舉的結果。一切都在他們的掌控之中。很可能是這樣,這對我們的國家來說是非常悲哀的。",
"這一切(發生的事情)都非常奇怪。在選舉後的幾天,我們見證了這場試圖決定勝者的操作。即使許多關鍵州仍然在計算選票。",
"我們必須繼續依循憲法流程,為維護選舉的誠信,我們將確保計算每張合法選票,不計算任何一張非法選票。這不只是為了尊重那7,400萬選我的美國人,也是為了確保美國人能對這場選舉、以致未來的選舉還能保有信心。",
"今天我將詳細說明我們近幾週所揭露的那些驚人、不符合常規的濫權舞弊行為,呈現給各位我們所發現的證據中的一小部分。事實上我們有大量的證據。",
"我想先和各位解釋腐敗的郵寄選票系統。",
"民主黨是如何系統性地策劃,特別使搖擺州的選票得以被修改。因為他們必須在(那幾個州)獲得勝選。他們不知道的是,事情比他們預期的要困難許多,因為我們在所有搖擺州都遙遙領先,比他們認為的多太多了。",
"我們老早就知道,民主黨的政治機器是如何參與選舉舞弊。從底特律到費城,從密爾沃基市到亞特蘭大,太多地方。",
"今年所不同的是,民主黨積極推動印刷並寄出數十、數百萬張郵寄選票。寄到不知名的收件人手裡,沒有任何保護措施。這讓舞弊和濫權演變到前所未見的程度。",
"利用疫情作為藉口,民主黨的法官和政客,在投票前幾個月甚至幾週前大肆修改選舉章程。",
"11月3號的選舉,我們的立法者很少參與其中,但按憲法要求他們是該參與其中。但非常罕見。不過,你會看到隨著我們持續提起訴訟,所發生的一切,這場選舉絕對都是違憲的。",
"包括內華達和加州等許多州,向選民名單上的每個人郵寄了(總數)超百萬的有效選票,無論這些人是否要求郵寄選票,無論是死是活,他們都收到了選票。",
"在其它州,如明尼蘇達、密歇根州或威斯康星州,在今年年中就發起了普遍缺席選票,(他們)向所有名單上的選民發送缺席選票申請表。無論這些人的身分為何,如此大量的擴充投票數量使欺詐的閘門大大敞開。",
"眾所周知的事實是,這些選票中塞滿了沒有合法投票權的人的選票,包括那些死者、搬走的、甚至是在我們國家沒有公民身分的人。更有甚者,這些紀錄充斥著各種錯誤,錯誤地址、重複輸入和其它問題,而這些錯誤都沒有被質疑,從來沒有被質疑過。",
"在搖擺州的許多縣內,登記選民的人數遠超出合格適齡的選民人數,包括密歇根州的67個縣。所有這些都是證據。",
"在威斯康辛,該州的選舉委員會無法證實其中超過十萬人的居民身分,卻拒絕將這些人從選民名冊中移除。他們知道為什麼這樣。",
"我知道,他們是非法選民。荒謬的是,儘管到了2020年,我們竟沒有任何方法來核實那些投票選民的合法性。",
"而這是一次如此重要的選舉,我們無法確定他們是誰?是否是該州居民?甚或是他們是否是美國公民?",
"我們無法得知。我們(發現)在所有搖擺州都有重大違規或徹底的欺詐行為。其票數遠遠超過反轉一個州的(選舉)結果所需的票數。",
"換句話說,以威斯康星州為例。我們在選舉日當晚(得票)遠遠超前,他們最終使我們奇蹟般地輸掉了2萬票。",
"我可以在這裡向您展示,在威斯康星州,我們領先了許多,然而在凌晨3點42分出現了這樣一個大量的灌票,大多數是拜登,幾乎全是給拜登。直到今天,每個人都在試圖弄清楚它的來源。",
"但我從大贏變成小輸,就在這凌晨3點42分,就在威斯康星。",
"這是一件糟糕、糟糕、非常糟糕的事。但是,我們將擁有超出許多倍的、與推翻該州所需的2萬張選票相比的票數。",
"如果我們對舞弊的了解正確,喬·拜登不能當總統。",
"我們談的是數十萬的選票。我們談論的數字是前所未見的。",
"舉個例子,在某個州,我們落後7000票,但後來我們找到2萬、5萬、10萬、20萬的異議或舞弊選票,其中包括那些未經共和黨監票員驗證的選票。因為這些監票員被鎖在門外不被允許查看這些選票。",
"還有那些11月3日參加現場投票的人,他們都為能投票感到興奮,他們很開心,以身為美國公民為傲。他們在現場表示他們想要投票,然而他們被告知他們不能投票。",
"「很抱歉」,他們被告知,「很抱歉,你已經投過郵寄選票了。恭喜你,我們已經收到了你們的選票,你們不能投票。」他們不知道該如何是好,他們投訴無門,只好離開現場,說這很奇怪。但是也有許多人強烈地抗議、投訴。",
"在很多情況下,他們填寫了臨時選票,但他們的選票沒被用上。事實上,這些選票全是投給川普的。換句話說,他們去現場投票,卻被告知已經投過票了,但他們其實尚未投票,他們只好離開,感到非常喪氣。他們失去了對我們選舉系統的信心。我想向各位更新我們的努力成果,曝光在那荒謬、漫長的11月3日選舉中所發生的大面積選舉舞弊和各種不正常的現象。",
"我們以前有所謂的「選舉日」,現在卻拖延成好幾個選舉週、選舉月,這段時間裡許多不好的事發生了,特別是我們得去證明那些原本我們不需要去驗證的事,才得以執行我們最偉大的特權——選舉權。",
"作為總統,我責無旁貸,保護這個國家的法律和憲法,所以我決心保障我們的選舉系統。",
"而這個系統正遭受合謀攻擊。在總統選舉前的幾個月,我們被多次警告,不要過早宣告我們的勝選;我們反覆被告知,這場選舉將耗時幾週甚至幾個月來分出勝、來數缺席者選票,並確認結果。",
"我的對手被告知:「可以與選舉保持距離,不需要競選活動。我們不需要你。我們搞定了,這場選舉已經結束。」",
"實際上,他們的表現得好像他們早已知道了這場選舉的結果。一切都在他們的掌控之中。很可能是這樣,這對我們的國家來說是非常悲哀的。",
"這一切(發生的事情)都非常奇怪。在選舉後的幾天,我們見證了這場試圖決定勝者的操作。即使許多關鍵州仍然在計算選票。",
"我們必須繼續依循憲法流程,為維護選舉的誠信,我們將確保計算每張合法選票,不計算任何一張非法選票。這不只是為了尊重那7,400萬選我的美國人,也是為了確保美國人能對這場選舉、以致未來的選舉還能保有信心。",
"今天我將詳細說明我們近幾週所揭露的那些驚人、不符合常規的濫權舞弊行為,呈現給各位我們所發現的證據中的一小部分。事實上我們有大量的證據。",
"我想先和各位解釋腐敗的郵寄選票系統。",
"民主黨是如何系統性地策劃,特別使搖擺州的選票得以被修改。因為他們必須在(那幾個州)獲得勝選。他們不知道的是,事情比他們預期的要困難許多,因為我們在所有搖擺州都遙遙領先,比他們認為的多太多了。",
"我們老早就知道,民主黨的政治機器是如何參與選舉舞弊。從底特律到費城,從密爾沃基市到亞特蘭大,太多地方。",
"今年所不同的是,民主黨積極推動印刷並寄出數十、數百萬張郵寄選票。寄到不知名的收件人手裡,沒有任何保護措施。這讓舞弊和濫權演變到前所未見的程度。",
"利用疫情作為藉口,民主黨的法官和政客,在投票前幾個月甚至幾週前大肆修改選舉章程。",
"11月3號的選舉,我們的立法者很少參與其中,但按憲法要求他們是該參與其中。但非常罕見。不過,你會看到隨著我們持續提起訴訟,所發生的一切,這場選舉絕對都是違憲的。",
"包括內華達和加州等許多州,向選民名單上的每個人郵寄了(總數)超百萬的有效選票,無論這些人是否要求郵寄選票,無論是死是活,他們都收到了選票。",
"在其它州,如明尼蘇達、密歇根州或威斯康星州,在今年年中就發起了普遍缺席選票,(他們)向所有名單上的選民發送缺席選票申請表。無論這些人的身分為何,如此大量的擴充投票數量使欺詐的閘門大大敞開。",
"眾所周知的事實是,這些選票中塞滿了沒有合法投票權的人的選票,包括那些死者、搬走的、甚至是在我們國家沒有公民身分的人。更有甚者,這些紀錄充斥著各種錯誤,錯誤地址、重複輸入和其它問題,而這些錯誤都沒有被質疑,從來沒有被質疑過。",
"在搖擺州的許多縣內,登記選民的人數遠超出合格適齡的選民人數,包括密歇根州的67個縣。所有這些都是證據。",
"在威斯康辛,該州的選舉委員會無法證實其中超過十萬人的居民身分,卻拒絕將這些人從選民名冊中移除。他們知道為什麼這樣。",
"我知道,他們是非法選民。荒謬的是,儘管到了2020年,我們竟沒有任何方法來核實那些投票選民的合法性。",
"而這是一次如此重要的選舉,我們無法確定他們是誰?是否是該州居民?甚或是他們是否是美國公民?",
"我們無法得知。我們(發現)在所有搖擺州都有重大違規或徹底的欺詐行為。其票數遠遠超過反轉一個州的(選舉)結果所需的票數。",
"換句話說,以威斯康星州為例。我們在選舉日當晚(得票)遠遠超前,他們最終使我們奇蹟般地輸掉了2萬票。",
"我可以在這裡向您展示,在威斯康星州,我們領先了許多,然而在凌晨3點42分出現了這樣一個大量的灌票,大多數是拜登,幾乎全是給拜登。直到今天,每個人都在試圖弄清楚它的來源。",
"但我從大贏變成小輸,就在這凌晨3點42分,就在威斯康星。",
"這是一件糟糕、糟糕、非常糟糕的事。但是,我們將擁有超出許多倍的、與推翻該州所需的2萬張選票相比的票數。",
"如果我們對舞弊的了解正確,喬·拜登不能當總統。",
"我們談的是數十萬的選票。我們談論的數字是前所未見的。",
"舉個例子,在某個州,我們落後7000票,但後來我們找到2萬、5萬、10萬、20萬的異議或舞弊選票,其中包括那些未經共和黨監票員驗證的選票。因為這些監票員被鎖在門外不被允許查看這些選票。",
"還有那些11月3日參加現場投票的人,他們都為能投票感到興奮,他們很開心,以身為美國公民為傲。他們在現場表示他們想要投票,然而他們被告知他們不能投票。",
"「很抱歉」,他們被告知,「很抱歉,你已經投過郵寄選票了。恭喜你,我們已經收到了你們的選票,你們不能投票。」他們不知道該如何是好,他們投訴無門,只好離開現場,說這很奇怪。但是也有許多人強烈地抗議、投訴。",
"在很多情況下,他們填寫了臨時選票,但他們的選票沒被用上。事實上,這些選票全是投給川普的。換句話說,他們去現場投票,卻被告知已經投過票了,但他們其實尚未投票,他們只好離開,感到非常喪氣。他們失去了對我們選舉系統的信心。"
],
"placeholder": [
"我想向各位更新我們的努力成果,曝光在那荒謬、漫長的11月3日選舉中所發生的大面積選舉舞弊和各種不正常的現象。",
"我們以前有所謂的「選舉日」,現在卻拖延成好幾個選舉週、選舉月,這段時間裡許多不好的事發生了,特別是我們得去證明那些原本我們不需要去驗證的事,才得以執行我們最偉大的特權——選舉權。",
"作為總統,我責無旁貸,保護這個國家的法律和憲法,所以我決心保障我們的選舉系統。",
"而這個系統正遭受合謀攻擊。在總統選舉前的幾個月,我們被多次警告,不要過早宣告我們的勝選;我們反覆被告知,這場選舉將耗時幾週甚至幾個月來分出勝、來數缺席者選票,並確認結果。",
"我的對手被告知:「可以與選舉保持距離,不需要競選活動。我們不需要你。我們搞定了,這場選舉已經結束。」",
"實際上,他們的表現得好像他們早已知道了這場選舉的結果。一切都在他們的掌控之中。很可能是這樣,這對我們的國家來說是非常悲哀的。",
"這一切(發生的事情)都非常奇怪。在選舉後的幾天,我們見證了這場試圖決定勝者的操作。即使許多關鍵州仍然在計算選票。",
"我們必須繼續依循憲法流程,為維護選舉的誠信,我們將確保計算每張合法選票,不計算任何一張非法選票。這不只是為了尊重那7,400萬選我的美國人,也是為了確保美國人能對這場選舉、以致未來的選舉還能保有信心。",
"今天我將詳細說明我們近幾週所揭露的那些驚人、不符合常規的濫權舞弊行為,呈現給各位我們所發現的證據中的一小部分。事實上我們有大量的證據。",
"我想先和各位解釋腐敗的郵寄選票系統。",
"民主黨是如何系統性地策劃,特別使搖擺州的選票得以被修改。因為他們必須在(那幾個州)獲得勝選。他們不知道的是,事情比他們預期的要困難許多,因為我們在所有搖擺州都遙遙領先,比他們認為的多太多了。",
"我們老早就知道,民主黨的政治機器是如何參與選舉舞弊。從底特律到費城,從密爾沃基市到亞特蘭大,太多地方。",
"今年所不同的是,民主黨積極推動印刷並寄出數十、數百萬張郵寄選票。寄到不知名的收件人手裡,沒有任何保護措施。這讓舞弊和濫權演變到前所未見的程度。",
"利用疫情作為藉口,民主黨的法官和政客,在投票前幾個月甚至幾週前大肆修改選舉章程。",
"11月3號的選舉,我們的立法者很少參與其中,但按憲法要求他們是該參與其中。但非常罕見。不過,你會看到隨著我們持續提起訴訟,所發生的一切,這場選舉絕對都是違憲的。",
"包括內華達和加州等許多州,向選民名單上的每個人郵寄了(總數)超百萬的有效選票,無論這些人是否要求郵寄選票,無論是死是活,他們都收到了選票。",
"在其它州,如明尼蘇達、密歇根州或威斯康星州,在今年年中就發起了普遍缺席選票,(他們)向所有名單上的選民發送缺席選票申請表。無論這些人的身分為何,如此大量的擴充投票數量使欺詐的閘門大大敞開。",
"眾所周知的事實是,這些選票中塞滿了沒有合法投票權的人的選票,包括那些死者、搬走的、甚至是在我們國家沒有公民身分的人。更有甚者,這些紀錄充斥著各種錯誤,錯誤地址、重複輸入和其它問題,而這些錯誤都沒有被質疑,從來沒有被質疑過。",
"在搖擺州的許多縣內,登記選民的人數遠超出合格適齡的選民人數,包括密歇根州的67個縣。所有這些都是證據。",
"在威斯康辛,該州的選舉委員會無法證實其中超過十萬人的居民身分,卻拒絕將這些人從選民名冊中移除。他們知道為什麼這樣。",
"我知道,他們是非法選民。荒謬的是,儘管到了2020年,我們竟沒有任何方法來核實那些投票選民的合法性。",
"而這是一次如此重要的選舉,我們無法確定他們是誰?是否是該州居民?甚或是他們是否是美國公民?",
"我們無法得知。我們(發現)在所有搖擺州都有重大違規或徹底的欺詐行為。其票數遠遠超過反轉一個州的(選舉)結果所需的票數。",
"換句話說,以威斯康星州為例。我們在選舉日當晚(得票)遠遠超前,他們最終使我們奇蹟般地輸掉了2萬票。",
"我可以在這裡向您展示,在威斯康星州,我們領先了許多,然而在凌晨3點42分出現了這樣一個大量的灌票,大多數是拜登,幾乎全是給拜登。直到今天,每個人都在試圖弄清楚它的來源。",
"但我從大贏變成小輸,就在這凌晨3點42分,就在威斯康星。",
"這是一件糟糕、糟糕、非常糟糕的事。但是,我們將擁有超出許多倍的、與推翻該州所需的2萬張選票相比的票數。",
"如果我們對舞弊的了解正確,喬·拜登不能當總統。",
"我們談的是數十萬的選票。我們談論的數字是前所未見的。",
"舉個例子,在某個州,我們落後7000票,但後來我們找到2萬、5萬、10萬、20萬的異議或舞弊選票,其中包括那些未經共和黨監票員驗證的選票。因為這些監票員被鎖在門外不被允許查看這些選票。",
"還有那些11月3日參加現場投票的人,他們都為能投票感到興奮,他們很開心,以身為美國公民為傲。他們在現場表示他們想要投票,然而他們被告知他們不能投票。",
"「很抱歉」,他們被告知,「很抱歉,你已經投過郵寄選票了。恭喜你,我們已經收到了你們的選票,你們不能投票。」他們不知道該如何是好,他們投訴無門,只好離開現場,說這很奇怪。但是也有許多人強烈地抗議、投訴。",
"在很多情況下,他們填寫了臨時選票,但他們的選票沒被用上。事實上,這些選票全是投給川普的。換句話說,他們去現場投票,卻被告知已經投過票了,但他們其實尚未投票,他們只好離開,感到非常喪氣。他們失去了對我們選舉系統的信心。我想向各位更新我們的努力成果,曝光在那荒謬、漫長的11月3日選舉中所發生的大面積選舉舞弊和各種不正常的現象。",
"我們以前有所謂的「選舉日」,現在卻拖延成好幾個選舉週、選舉月,這段時間裡許多不好的事發生了,特別是我們得去證明那些原本我們不需要去驗證的事,才得以執行我們最偉大的特權——選舉權。",
"作為總統,我責無旁貸,保護這個國家的法律和憲法,所以我決心保障我們的選舉系統。",
"而這個系統正遭受合謀攻擊。在總統選舉前的幾個月,我們被多次警告,不要過早宣告我們的勝選;我們反覆被告知,這場選舉將耗時幾週甚至幾個月來分出勝、來數缺席者選票,並確認結果。",
"我的對手被告知:「可以與選舉保持距離,不需要競選活動。我們不需要你。我們搞定了,這場選舉已經結束。」",
"實際上,他們的表現得好像他們早已知道了這場選舉的結果。一切都在他們的掌控之中。很可能是這樣,這對我們的國家來說是非常悲哀的。",
"這一切(發生的事情)都非常奇怪。在選舉後的幾天,我們見證了這場試圖決定勝者的操作。即使許多關鍵州仍然在計算選票。",
"我們必須繼續依循憲法流程,為維護選舉的誠信,我們將確保計算每張合法選票,不計算任何一張非法選票。這不只是為了尊重那7,400萬選我的美國人,也是為了確保美國人能對這場選舉、以致未來的選舉還能保有信心。",
"今天我將詳細說明我們近幾週所揭露的那些驚人、不符合常規的濫權舞弊行為,呈現給各位我們所發現的證據中的一小部分。事實上我們有大量的證據。",
"我想先和各位解釋腐敗的郵寄選票系統。",
"民主黨是如何系統性地策劃,特別使搖擺州的選票得以被修改。因為他們必須在(那幾個州)獲得勝選。他們不知道的是,事情比他們預期的要困難許多,因為我們在所有搖擺州都遙遙領先,比他們認為的多太多了。",
"我們老早就知道,民主黨的政治機器是如何參與選舉舞弊。從底特律到費城,從密爾沃基市到亞特蘭大,太多地方。",
"今年所不同的是,民主黨積極推動印刷並寄出數十、數百萬張郵寄選票。寄到不知名的收件人手裡,沒有任何保護措施。這讓舞弊和濫權演變到前所未見的程度。",
"利用疫情作為藉口,民主黨的法官和政客,在投票前幾個月甚至幾週前大肆修改選舉章程。",
"11月3號的選舉,我們的立法者很少參與其中,但按憲法要求他們是該參與其中。但非常罕見。不過,你會看到隨著我們持續提起訴訟,所發生的一切,這場選舉絕對都是違憲的。",
"包括內華達和加州等許多州,向選民名單上的每個人郵寄了(總數)超百萬的有效選票,無論這些人是否要求郵寄選票,無論是死是活,他們都收到了選票。",
"在其它州,如明尼蘇達、密歇根州或威斯康星州,在今年年中就發起了普遍缺席選票,(他們)向所有名單上的選民發送缺席選票申請表。無論這些人的身分為何,如此大量的擴充投票數量使欺詐的閘門大大敞開。",
"眾所周知的事實是,這些選票中塞滿了沒有合法投票權的人的選票,包括那些死者、搬走的、甚至是在我們國家沒有公民身分的人。更有甚者,這些紀錄充斥著各種錯誤,錯誤地址、重複輸入和其它問題,而這些錯誤都沒有被質疑,從來沒有被質疑過。",
"在搖擺州的許多縣內,登記選民的人數遠超出合格適齡的選民人數,包括密歇根州的67個縣。所有這些都是證據。",
"在威斯康辛,該州的選舉委員會無法證實其中超過十萬人的居民身分,卻拒絕將這些人從選民名冊中移除。他們知道為什麼這樣。",
"我知道,他們是非法選民。荒謬的是,儘管到了2020年,我們竟沒有任何方法來核實那些投票選民的合法性。",
"而這是一次如此重要的選舉,我們無法確定他們是誰?是否是該州居民?甚或是他們是否是美國公民?",
"我們無法得知。我們(發現)在所有搖擺州都有重大違規或徹底的欺詐行為。其票數遠遠超過反轉一個州的(選舉)結果所需的票數。",
"換句話說,以威斯康星州為例。我們在選舉日當晚(得票)遠遠超前,他們最終使我們奇蹟般地輸掉了2萬票。",
"我可以在這裡向您展示,在威斯康星州,我們領先了許多,然而在凌晨3點42分出現了這樣一個大量的灌票,大多數是拜登,幾乎全是給拜登。直到今天,每個人都在試圖弄清楚它的來源。",
"但我從大贏變成小輸,就在這凌晨3點42分,就在威斯康星。",
"這是一件糟糕、糟糕、非常糟糕的事。但是,我們將擁有超出許多倍的、與推翻該州所需的2萬張選票相比的票數。",
"如果我們對舞弊的了解正確,喬·拜登不能當總統。",
"我們談的是數十萬的選票。我們談論的數字是前所未見的。",
"舉個例子,在某個州,我們落後7000票,但後來我們找到2萬、5萬、10萬、20萬的異議或舞弊選票,其中包括那些未經共和黨監票員驗證的選票。因為這些監票員被鎖在門外不被允許查看這些選票。",
"還有那些11月3日參加現場投票的人,他們都為能投票感到興奮,他們很開心,以身為美國公民為傲。他們在現場表示他們想要投票,然而他們被告知他們不能投票。",
"「很抱歉」,他們被告知,「很抱歉,你已經投過郵寄選票了。恭喜你,我們已經收到了你們的選票,你們不能投票。」他們不知道該如何是好,他們投訴無門,只好離開現場,說這很奇怪。但是也有許多人強烈地抗議、投訴。",
"在很多情況下,他們填寫了臨時選票,但他們的選票沒被用上。事實上,這些選票全是投給川普的。換句話說,他們去現場投票,卻被告知已經投過票了,但他們其實尚未投票,他們只好離開,感到非常喪氣。他們失去了對我們選舉系統的信心。"
],
"required": true
},
{
"type": "text",
"key": "sense",
"value": "tension",
"placeholder": "tension",
"required": true
},
{
"type": "dict",
"key": "user_defined",
"value": {"positive": [], "negative": [], "cursing": []},
"placeholder": {"positive": ["邪惡", "地獄"], "negative": ["正義", "天堂"]} ,
"required": false
}
]
}
SENSE2 Visual
HTTP Request
POST https://api.droidtown.co/KeyMoji/Toolkit/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。 將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。 此範例為 sense2。 |
| results | list | [] | 對應參數sense結果的results欄位,不可為空值。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
- Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 |
||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid result.: results內容不符合指定參數sense。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 sense2。 |
| result | dict | 將繪製的圖表結果存儲至 dict,內容包含以下 |
| - name: 圖表的檔案名稱。 | ||
- base64: base64格式的圖檔。 |
範例程式
{
"url": "https://api.droidtown.co/KeyMoji/Toolkit/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "sense",
"value": "sense2",
"placeholder": "sense2",
"required": true
},
{
"type": "dict",
"key": "results",
"value": [
{"cursing": false,
"input_str": "高興的要死",
"score": 0.7483,
"sentiment": "positive"}
],
"placeholder": [
{"cursing": false,
"input_str": "高興的要死",
"score": 0.7483,
"sentiment": "positive"}
],
"required": false
}
]
}
SENSE8 Visual
HTTP Request
POST https://api.droidtown.co/KeyMoji/Toolkit/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。 將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。 此範例為 sense8。 |
| results | list | [] | 對應參數sense結果的results欄位,不可為空值。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
- Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 |
||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid result.: results內容不符合指定參數sense。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 sense8。 |
| result | dict | 將繪製的圖表結果存儲至 dict,內容包含以下 |
| - name: 圖表壓縮檔的名稱。 | ||
- base64: base64格式的壓縮檔。 |
範例程式
{
"url": "https://api.droidtown.co/KeyMoji/Toolkit/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "sense",
"value": "sense8",
"placeholder": "sense8",
"required": true
},
{
"type": "dict",
"key": "results",
"value": [{
"input_str": "高興的要死",
"Anger": 2.0356,
"Anticipation": 7.4765,
"Disgust": 1.2923,
"Fear": 2.4753,
"Joy": 7.7804,
"Sadness": 3.1816,
"Surprise": 7.7534,
"Trust": 7.5461
}],
"placeholder": [{
"input_str": "高興的要死",
"Anger": 2.0356,
"Anticipation": 7.4765,
"Disgust": 1.2923,
"Fear": 2.4753,
"Joy": 7.7804,
"Sadness": 3.1816,
"Surprise": 7.7534,
"Trust": 7.5461
}],
"required": true
}
]
}
Tension Visual
HTTP Request
POST https://api.droidtown.co/KeyMoji/Toolkit/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。KeyMoji Docker 版本無需設定此參數。 |
| keymoji_key | str | "" | 在本站購買KeyMoji服務,完成付費後取得的一個具有 31 字符長度的字串。KeyMoji Docker 版本無需設定此參數。 |
| sense | str | "" | 可為 "sense2"、"sense8" 或 "tension",不可為空值。 將情緒偵測結果投射到二維 (SENSE2)、八維 (SENSE8) 的情緒空間或是文本權重效果獨立成「情緒張力」(Tension) 的結果。 此範例為 tension。 |
| results | list | [] | 對應參數sense結果的results欄位,不可為空值。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並收到情緒偵測結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成情緒偵測作業。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Your input_str is too long (over 6000 characters.): input_str 超過 6000 字符。 | ||
- Authentication failed.: 無法驗証您的帳號,或是未購買KeyMoji方案。請再檢查一次您使用的帳號是否正確。 |
||
| - Invalid KeyMoji key.: 無效的 keymoji_key。請再檢查一次您的 keymoji_key 是否正確。 | ||
| - Invalid result.: results內容不符合指定參數sense。 | ||
| - Invalid sense.: sense 所指定的參數不存在。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| sense | str | 此次情緒偵測所使用的功能。此範例為 tension。 |
| result | dict | 將繪製的圖表結果存儲至 dict,內容包含以下 |
| - name: 圖表的檔案名稱。 | ||
- base64: base64格式的圖檔。 |
範例程式
{
"url": "https://api.droidtown.co/KeyMoji/Toolkit/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "keymoji_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 keymoji_key。若使用空字串,則預設使用每小時 2000 字的公用額度。",
"required": true
},
{
"type": "text",
"key": "sense",
"value": "tension",
"placeholder": "tension",
"required": true
},
{
"type": "dict",
"key": "results",
"value": [0.1791, 0.1667, 0.1, 0.1622, 0.1558, 0.1528, 0.1061, 0.2083, 0.1026, 0.1951, 0.24],
"placeholder": [0.1791, 0.1667, 0.1, 0.1622, 0.1558, 0.1528, 0.1061, 0.2083, 0.1026, 0.1951, 0.24],
"required": true
}
]
}
Loki
Loki 服務介紹
Loki 全文是 Linguistic Oriented Keyword Interface (語言導向的關鍵詞介面),是新一代的自然語言理解 (Natural Language Understanding, NLU) 引擎。
基於句法分析的方式,自動產生 Python 的 Regular Expression (正則表示式) 的條件式 (if...else...) 區塊程式碼。
Loki 相較於微軟的 LUIS 或 Google DiaglogFlow 等利用機器學習或統計機率的傳統方案,在訓練資料量的需求上,能省下極大的功夫。
參考連結:
Loki 的釋出說明影片
Loki 自然語言理解引擎 佈署優勢
用 Loki 解中文的數學應用問題
Loki 快速上手指南
登入 Loki
在 https://api.droidtown.co/loki/ 登入開始使用Loki。
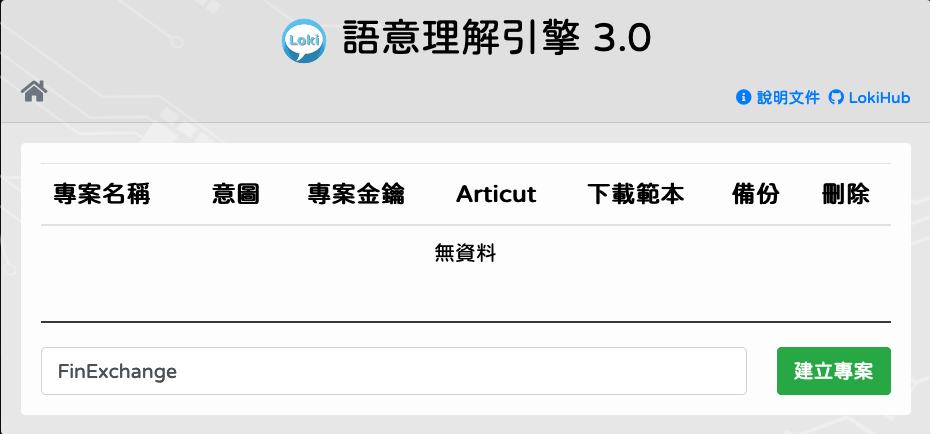
建立專案
輸入專案名稱 (僅接受英文 [a-z, A-Z]、數字 [0-9] 和底線 [_]),點擊[建立專案]。
建立基本意圖
進入
[專案]後點擊[建立基本意圖]。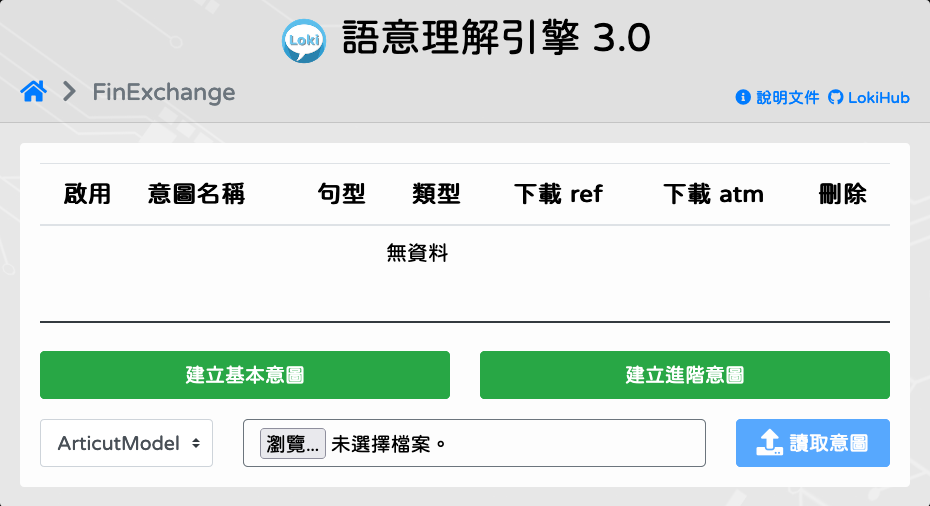
輸入意圖名稱 (僅接受英文 [a-z, A-Z]、數字 [0-9] 和底線 [_]),點擊
[建立意圖]。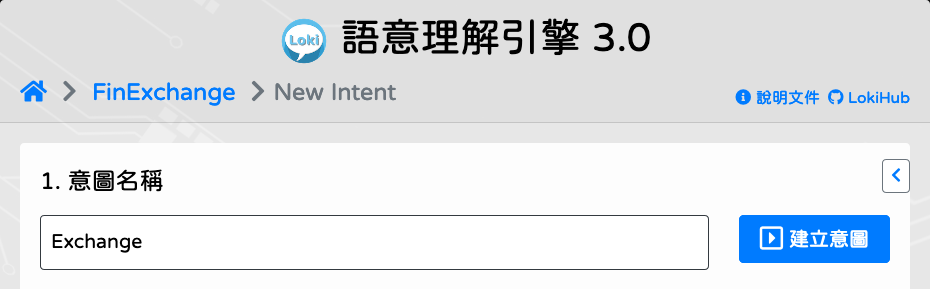
若有
自定義詞彙,可以自行新增;若無,則進入下一步。自定義詞彙中的 key 和 value 都會被拿來做為「自定詞彙」使用。比如說,當您要新增虛擬貨幣名稱做為「自定詞彙」時,我們建議可以採用這種方式使用:key: "_crypto_coin" value: ["狗狗幣", "Q幣", "以太幣"]這樣的好處是因為 key 也會被拿來當做自訂詞彙,所以我們就特別用一個「不太可能會出現」的詞彙來做 key (也就是_crypto_coin) 這麼一來,就能同時保有字典型式儲存的靈活性,也能知道「"狗狗幣", "Q幣", "以太幣"」指的是同一個東西。稍後如果 intent 的程式碼中需要和資料庫做查詢連結時,比較容易正規化。
SELECT _crypto_coin FROM ...
輸入意圖文句後點擊
[單句分析],建議一次一句,若有標點符號,系統會自動忽略。可大量輸入完再點擊[全句分析]。
勾選意圖所需
[參數](通常是會變動的值或詞彙,電腦需要計算的實體)。Loki 提供兩種方法勾選意圖參數:
Graph 勾選
[參數]

直接勾選
[參數]

PS. 若需要大量勾選相同參數名稱,請點選頁面右側
<開啟參數勾選工具

輸入版本號,點擊
[佈署模型]。
輸入文句點擊
[意圖分析],測試意圖文句,確認是否有偵測到第 4 步所勾選的意圖與參數。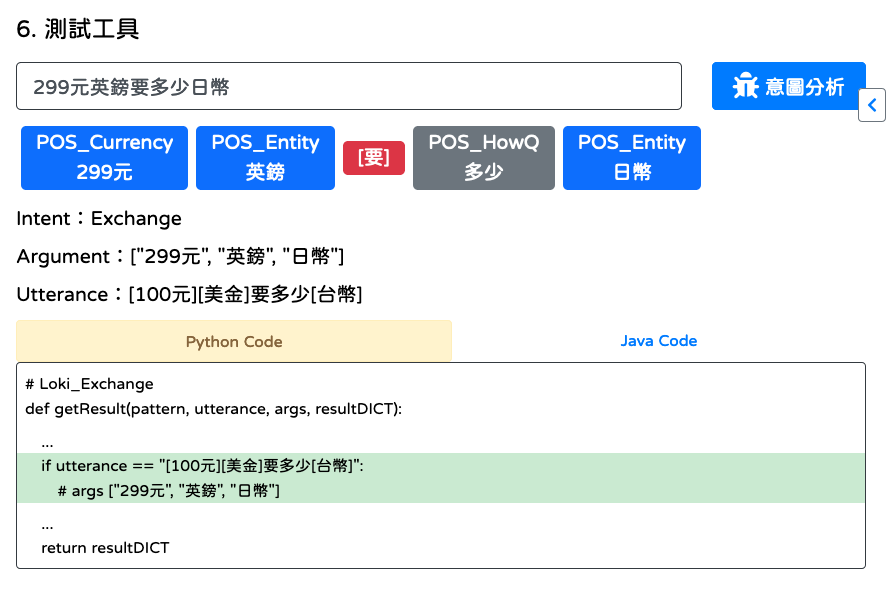
重複 4 至 6 步驟,直到全部訓練的文句皆可偵測其
意圖。
建立進階意圖
進入
[專案]後點擊[建立進階意圖]。輸入意圖名稱 (僅接受英文 [a-z, A-Z]、數字 [0-9] 和底線 [_]),點擊
[建立意圖]。若有
自定義詞彙,可以自行新增;若無,則進入下一步。輸入意圖文句後點擊
[分析],系統會賦予預設的正規表達式 (Regex),根據需求自行調整,最後點擊[檢驗]驗證正規表達式 (Regex) 是否適用於意圖文句。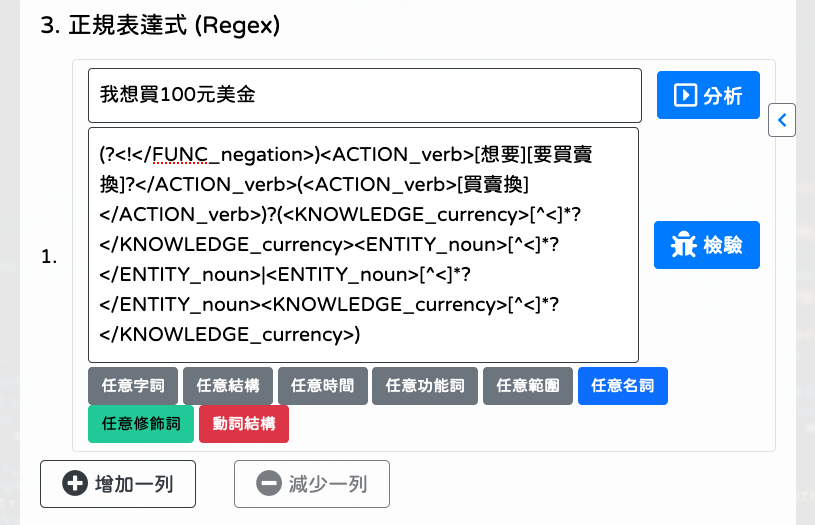
輸入版本號,點擊
[佈署模型]。
輸入文句點擊
[意圖分析],測試意圖文句,確認是否有偵測到意圖。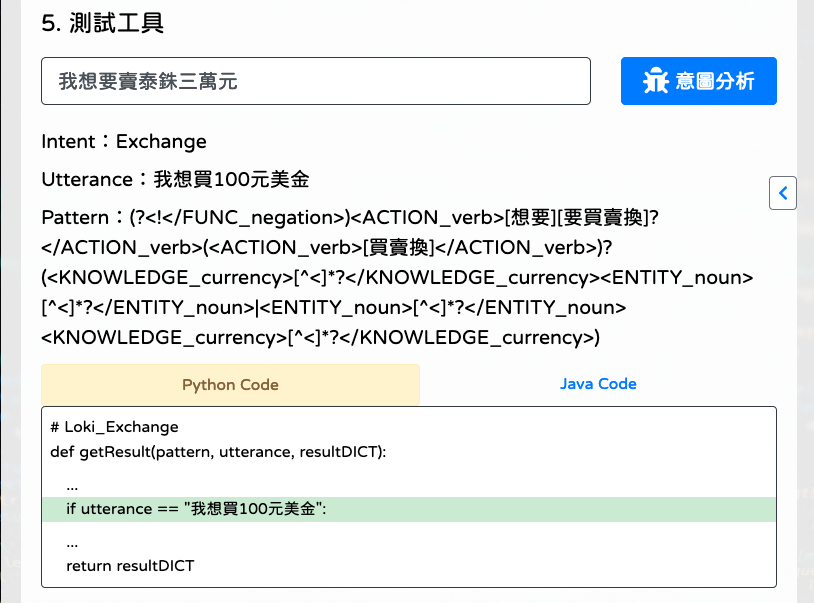
重複 4 至 5 步驟,直到全部訓練的文句皆可偵測其
意圖。
Loki 互動說明
簡單示意 Loki 如何使用相似結構 (Structural Pattern) 比對出最適合的 Utterance。
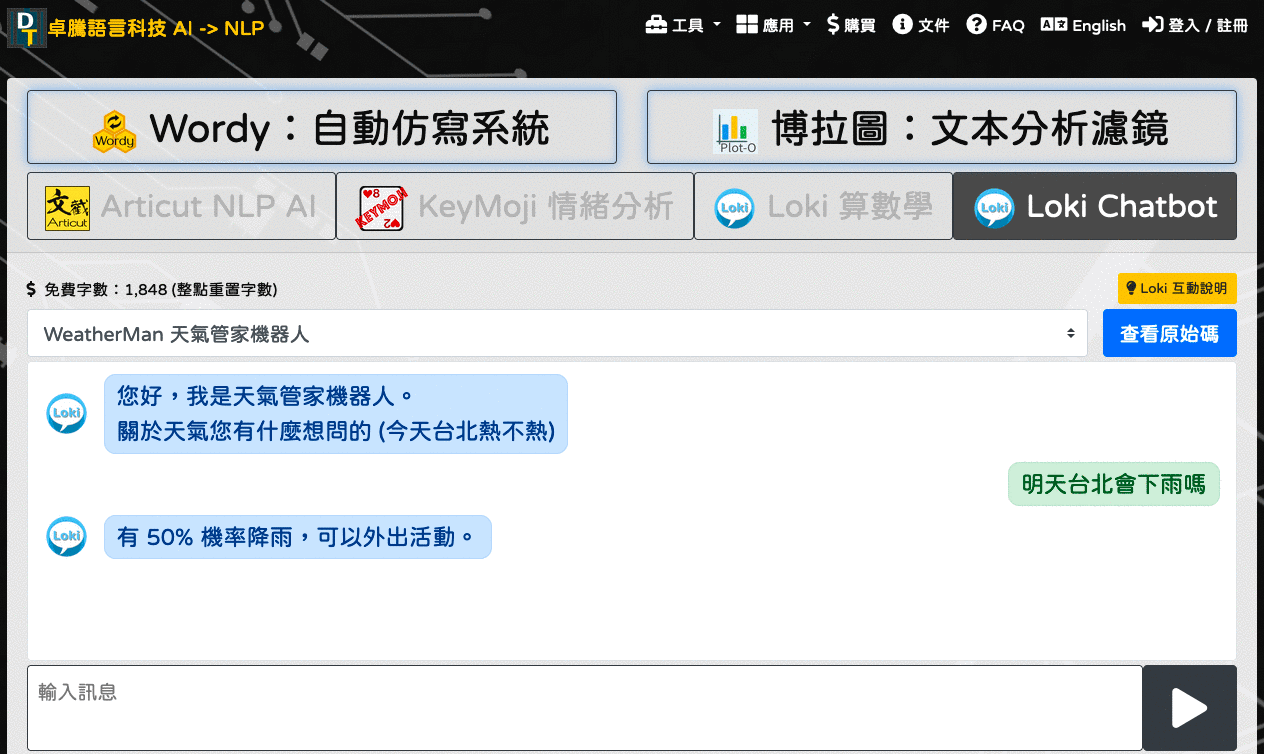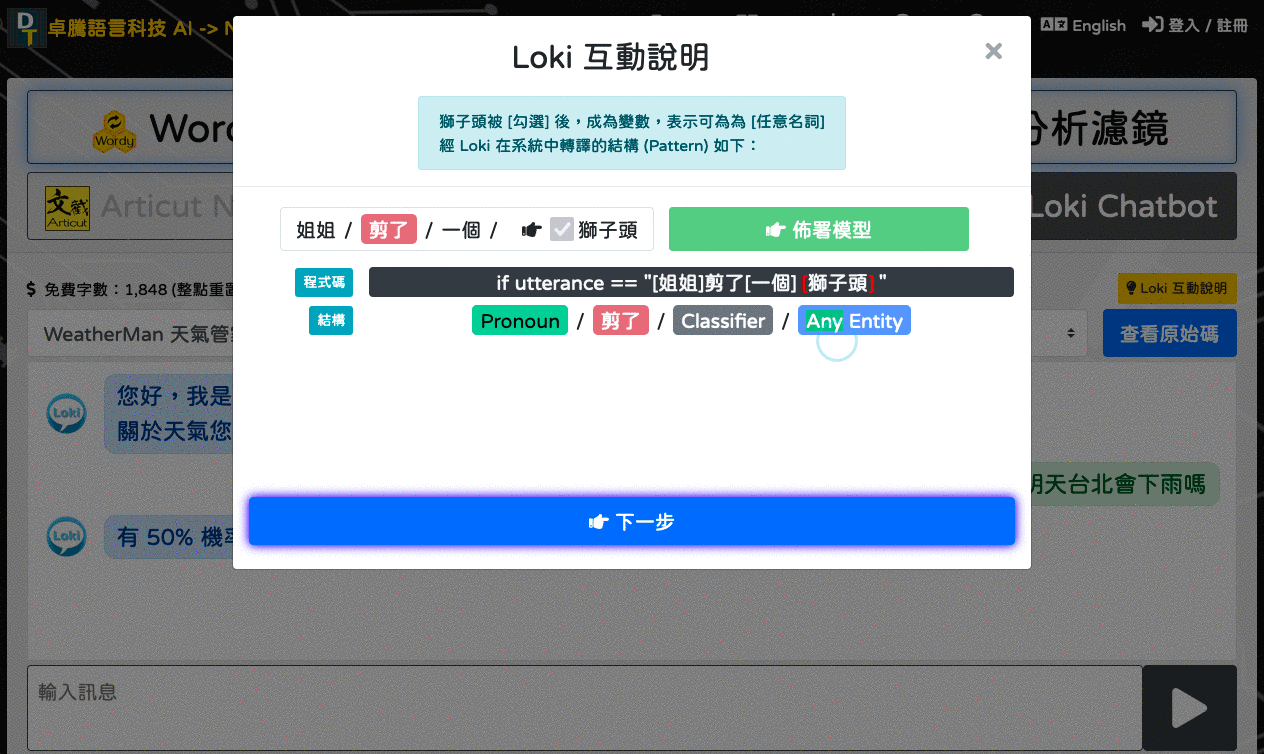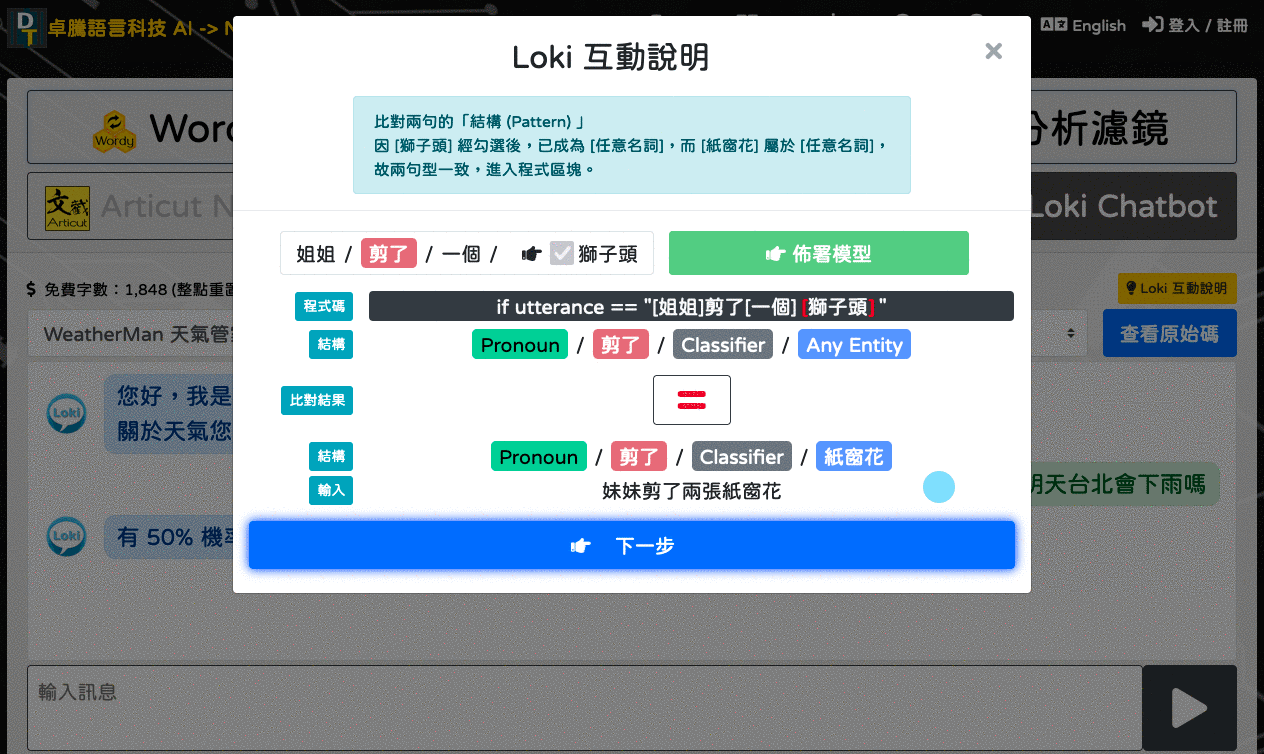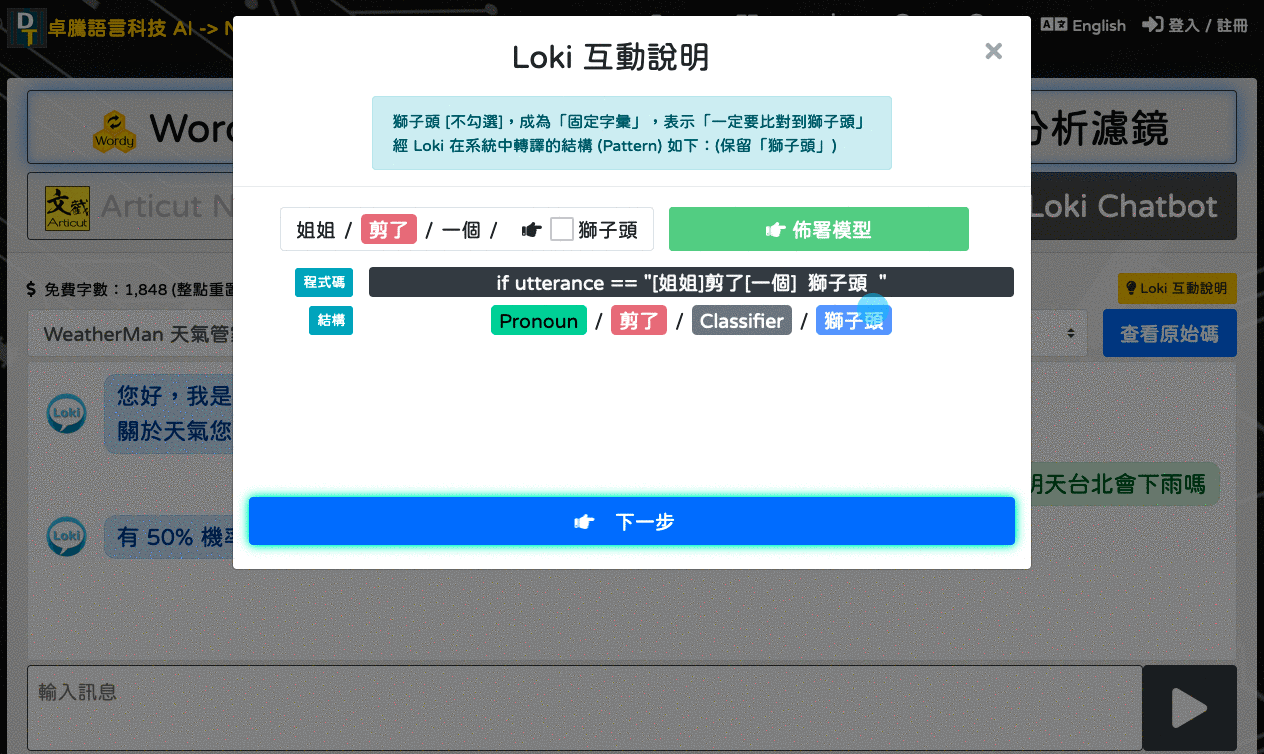
讀取 ATM 模型
登入 Loki
在 https://api.droidtown.co/loki/ 登入開始使用Loki。
建立專案
輸入專案名稱 (僅接受英文 [a-z, A-Z]、數字 [0-9] 和底線 [_]),點擊[建立專案]。
讀取模型
讀取 ArticutModel
在專案下方選擇 ArticutModel 並依序點擊 [瀏覽] > 選擇 ref 檔 (最多 10 個) > [讀取意圖]。

讀取 TXT 純文字
在專案下方選擇 Txt 並依序點擊 [瀏覽] > 選擇 txt 檔 (最多 10 個) > [讀取意圖]。

讀取 LUIS 模型
在專案下方選擇 LUIS 並依序點擊 [瀏覽] > 選擇 json 檔 (最多 10 個) > [讀取意圖]。

讀取 DialogFlow 模型
在專案下方選擇 DialogFlow 並依序點擊 [瀏覽] > 選擇 json 檔 (最多 10 個) > [讀取意圖]。

分析並佈署模型
後續請從 快速上手指南步驟 4 繼續完成。
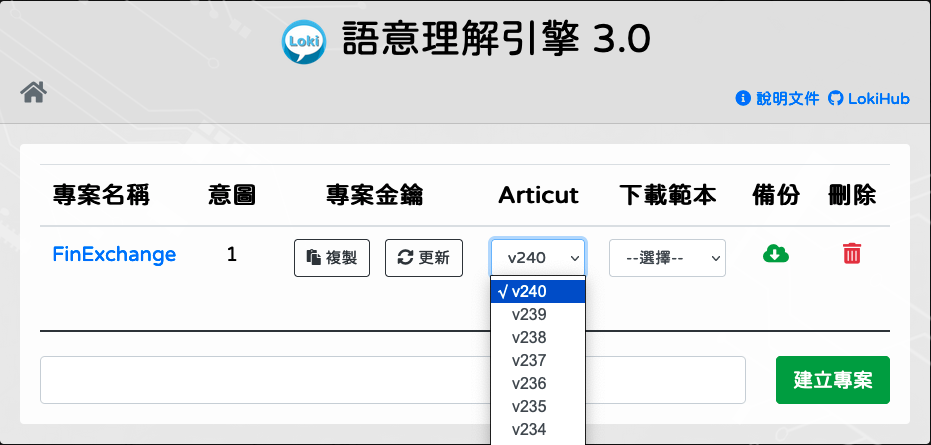
更換 Articut 版本
Loki 專案預設使用最新版的 Articut,也能讓使用者選擇偏好的版本。
登入 Loki
在 https://api.droidtown.co/loki/ 登入開始使用Loki。
更換專案 Articut 版本
在 Articut 下拉選單中選擇要使用的版本,轉換版本需要一點時間,請耐心等待。
更換版本後,進入
意圖將4. 勾選意圖所需參數區塊中重新勾選紅底的參數。完成後點擊
[佈署模型]。
使用 Loki 範本
Loki 目前提供 Python 和 Java (Android) 兩種程式範本,未來會支援更多的程式語言。
編譯專案意圖的計算邏輯
回到 Loki 首頁,點擊
[專案範本]的程式語言 (如:Python) 開始下載。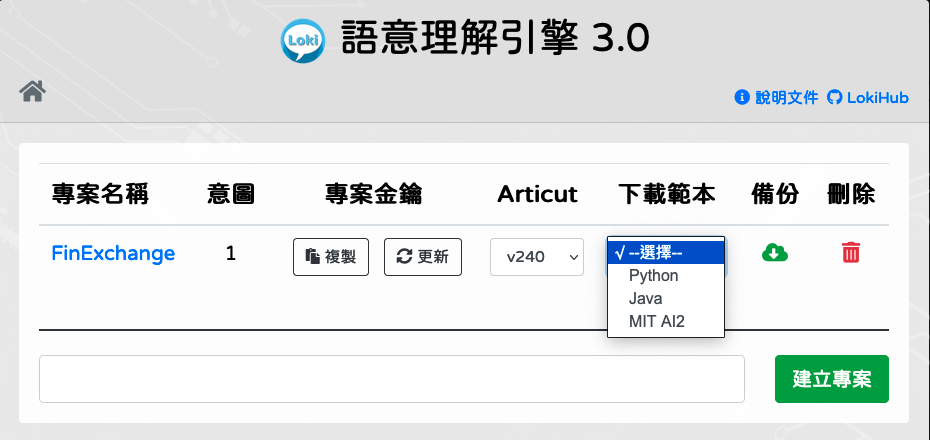
解壓縮 .zip 檔案。檔案目錄結構如下:
Project.py
intent/Loki_Intent.py
在
Project.py檔案,填上USERNAME (使用者帳號)和LOKI_KEY (專案金鑰)。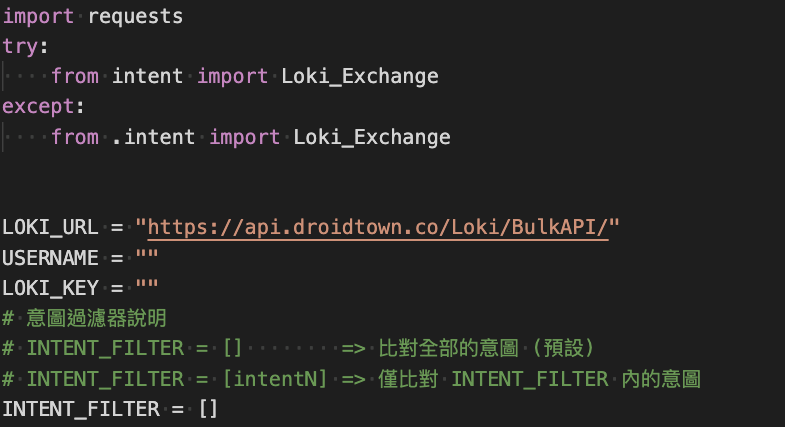
在
intent/Loki_Intent.py檔案,開始編譯意圖語意的計算方法。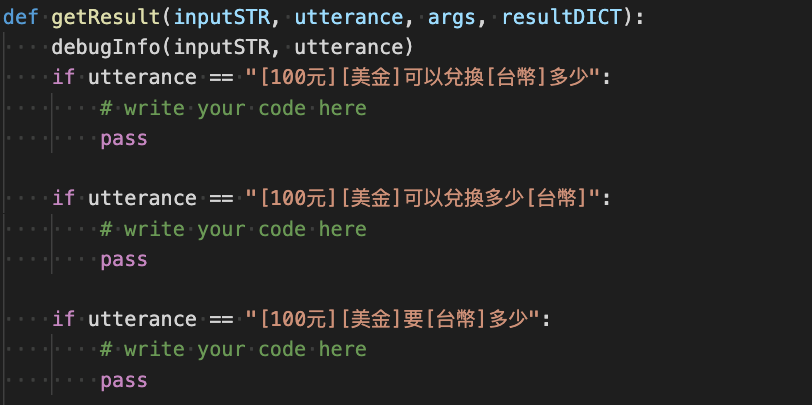
導入專案開始使用
Loki。
更新 Loki 範本意圖
Loki 目前提供 Python 的意圖更新工具。
下載新的 Loki 範本,並將新的
intent資料夾放入舊範本的project/intent/目錄下,並改名爲intent_new。
執行
Updater.py並指定新舊意圖的目錄位置。-o指定舊意圖目錄位置-n指定新意圖目錄位置python3 Updater.py -o ./ -n ./intent_new
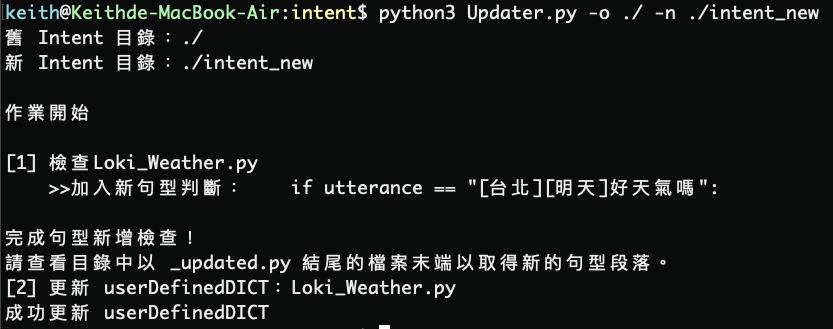
執行完畢後,如果意圖有變動的話,將會產生
Loki_意圖_updated.py,並將更新的 utterance 放至最下方。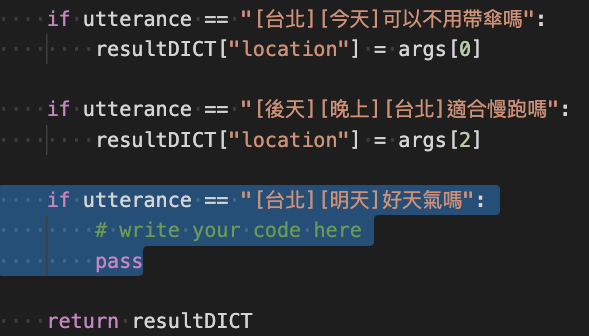
使用 Loki API
HTTP Request
POST https://api.droidtown.co/Loki/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Docker 版本無需設定此參數。 |
| loki_key | str | "" | 在本站使用 Loki 服務,建立專案後會取得一個具有 31 字符長度的字串。可建立多個意圖專案。Docker 版本無需設定此參數。 |
| input_str | str | "" | 將要送上 Loki 分析意圖的文字。注意!每次最大長度不得超過 2000 個字符。 |
| filter_list | list | [] | 預設為空列表,亦即檢查所有意圖。檢查指定的意圖。 |
| keyword_list | list | [] | 分類或分群模型使用的關鍵字列表。 |
| feature_list | list | [] | 分類或分群模型使用的分析參數。 可設置以下參數: feature_time feature_unit feature_noun feature_verb feature_userdefined feature_location feature_person feature_modifier feature_color feature_idiom feature_chmical |
| count | int | 1 | 取得分類或分群模型的結果數量,範圍為 1 ~ 5。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| progress_status | str | 分類或分群模型的進度狀態: |
| - processing: 分類或分群模型正在分析中。 | ||
| - completed: 分類或分群模型分析完畢。 | ||
| - failed: 分類或分群模型分析失敗。 | ||
| msg | str | 可能為以下的文字: |
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid project.: 無效的 loki_key。請再檢查一次您的 loki_key 是否正確,並確保專案內所有模型都已生成。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳斷詞結果的情況下,您帳號的餘額不會被扣除。 | ||
| - Loki GreedySlime is running, please try calling again later.: 分群模型正在分析結果中,請稍候再呼叫一次 API。 | ||
| - Loki NeuroKumoko is running, please try calling again later.: 分類模型正在分析結果中,請稍候再呼叫一次 API。 | ||
| - No matching intent.: 專案內未檢查到符合的意圖。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| - Success!: 執行成功。 | ||
| version | str | 本次斷詞作業所使用的演算法版本。 |
| word_count_balance | int | 您帳號下剩餘可用的字數值。 |
| results | list | Loki 意圖偵測結果。 |
| result_list | list | 分類或分群模型的分析結果。 |
範例程式
{
"url": "https://api.droidtown.co/Loki/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "loki_key",
"value": "fvUIyC&anirHZx#NGV%nxXSZbcCfJcS",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "100美金能換多少台幣",
"placeholder": "100美金能換多少台幣",
"required": true
},
{
"type": "list",
"key": "filter_list",
"value": ["Exchange"],
"placeholder": ["Exchange", "IntentName"],
"required": false
},
{
"type": "list",
"key": "keyword_list",
"value": [],
"placeholder": ["Keyword_1", "Keyword_2"],
"required": false
},
{
"type": "list",
"key": "feature_list",
"value": [],
"placeholder": ["feature_time", "feature_unit"],
"required": false
},
{
"type": "int",
"key": "count",
"value": 1,
"placeholder": 1,
"required": false
}
]
}
使用 Loki Bulk API
HTTP Request
POST https://api.droidtown.co/Loki/BulkAPI/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Docker 版本無需設定此參數。 |
| loki_key | str | "" | 在本站使用 Loki 服務,建立專案後會取得一個具有 31 字符長度的字串。可建立多個意圖專案。Docker 版本無需設定此參數。 |
| input_list | list | [] | 將要送上 Loki 分析意圖的文字。注意!每次最多 20 句且每句長度不得超過 2000 個字符。 |
| filter_list | list | [] | 預設為空列表,亦即檢查所有意圖。檢查指定的意圖。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid project.: 無效的 loki_key。請再檢查一次您的 loki_key 是否正確,並確保專案內所有模型都已生成。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳斷詞結果的情況下,您帳號的餘額不會被扣除。 | ||
| - No matching intent.: 專案內未檢查到符合的意圖。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| - Success!: 順利完成意圖偵測。 | ||
| - Your input is too many (over 20 sentence).: input_list 超過 20 個句子。 | ||
| version | str | 本次斷詞作業所使用的演算法版本。 |
| word_count_balance | int | 您帳號下剩餘可用的字數。 |
| result_list | list | Loki 意圖偵測結果。 |
範例程式
{
"url": "https://api.droidtown.co/Loki/BulkAPI/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "loki_key",
"value": "fvUIyC&anirHZx#NGV%nxXSZbcCfJcS",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "list",
"key": "input_list",
"value": [
"100美金能換多少台幣",
"台幣3000元能換多少美金"
],
"placeholder": [
"100美金能換多少台幣",
"台幣3000元能換多少美金"
],
"required": true
},
{
"type": "list",
"key": "filter_list",
"value": ["Exchange"],
"placeholder": ["Exchange"],
"required": false
}
]
}
使用 Loki Call
使用 Loki Call 來完成 Loki 各種任務。
HTTP Request
POST https://api.droidtown.co/Loki/Call/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Docker 版本無需設定此參數。 |
| loki_key | str | "" | 在本站使用 Loki 服務,建立專案後會取得一個具有 31 字符長度的字串。Docker 版本無需設定此參數。 |
| intent | str | "" | 意圖名稱,如果不存在會自動建立意圖。 |
| func | str | "" | 可設置為以下參數: |
| - check_model: 取得分類或分群模型的部屬狀態。 | |||
| - create_project: 建立新專案。 | |||
| - create_intent: 建立新意圖。 | |||
| - deploy_model: 部屬分類或分群模型。 | |||
| - get_info: 取得專案資訊。 | |||
| - get_source: 取得分群模型中 source 的原文出處。 | |||
| - get_utterance: 取得意圖內的所有句子。 | |||
| - insert_assistant: 新增大量的 ChatGPT Assistant 內容。 | |||
- insert_document: 新增大量的分類或分群文件。注意!標題與內容相同不會新增。 |
|||
- insert_utterance: 新增大量的意圖句子。注意!相同結構的句子不會新增。 |
|||
| - match_utterance: 比對句子在意圖中是否有相同結構。 | |||
| - preview_alias: 預覽套用別名的內容。 | |||
| - reset_alias: 清空 Prompt 別名。 | |||
| - reset_userdefined: 清空自定義辭典。 | |||
| - run_alias: 套用別名並執行 ChatGPT API。 | |||
| - set_llm: 設定專案的 LLM。 | |||
- update_alias: 更新 Prompt 別名。原有的別名並不會消失。 |
|||
| - update_prompt: 更新 ChatGPT Prompt 設定。 | |||
- update_userdefined: 更新自定義辭典。原有的辭典並不會消失。 |
|||
| data | dict | "" | 根據 func 參數設置以下格式 |
| data.alias | dict | {} | 要更新的 Prompt 別名設定。{key: value_list}func: update_alias |
| data.api_key | str | "" | 設定專案生成模型的金鑰。 func: set_llm |
| data.assistant | dict | {} | 要新增的 ChatGPT Assistant 內容。{title: value, content: {key: value}}func: insert_assistant |
| data.checked_list | str[] | [] | 設定新增句子時自動勾選的詞性 (參考詞性標記)。 func: insert_utterance |
| data.chatbot | bool | False | 設定專案是否啟用 Chatbot 模式。 func: set_llm |
| data.document | dict | {} | 要新增到分類或分群的文件內容。{title: value, content: value, keyword: [], label: value}func: insert_document |
| data.endpoint | str | "" | 設定專案生成模型 (Azure ChatGPT) 的 endpoint。func: set_llm |
| data.language | str | "zh-tw" | 專案使用的語言,只能是 zh-tw 或 taigi。func: create_project |
| data.llm | str | "" | 設定專案使用的生成模型,只能是 OpenAI ChatGPT 或 Azure ChatGPT。func: set_llm |
| data.messages | dict | {} | 執行 ChatGPT API 的 messages 參數。[{role: user, content: value}]func: preview_alias run_alias |
| data.model | str | "" | 設定專案生成模型的版本。 func: set_llm |
| data.name | str | "" | 專案名稱。 func: create_project |
| data.prompt | dict | {} | 要更新的 ChatGPT Prompt 設定。{system: value, assistant: value, user: value}func: update_prompt |
| data.source | str | "" | 分群模型的 source。 func: get_source |
| data.type | str | "intent" "basic" |
專案的模型,只能是 intent / neuro_kumoko / greedy_slime。func: create_project意圖的類型,只能是 basic 或 advance。func: create_intent |
| data.user_defined | dict | {} | 要更新的自定義辭典。{key: value_list}func: update_userdefined |
| data.utterance | str[] | [] | 要分析的句子。 func: insert_utterance match_utterance |
| data.version | str | "latest" | Articut 版本。 func: create_project |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Alias mask failed: 套用 Prompt 別名失敗。 | ||
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Document already exist.: 已存在相同的文件。 | ||
| - Failure.: 任務執行失敗。 | ||
| - Invalid alias format.: 不合法的別名格式。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
- Invalid assistant format.: assistant 內容格式錯誤,請重新檢查上傳時的參數是否符合規則名稱。 |
||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
- Invalid language. (zh-tw / taigi): 專案使用的語言只能是 zh-tw 或 taigi。 |
||
| - Invalid model.: 不合法的生成模型。 | ||
| - Invalid project.: 無效的金鑰。請再檢查一次您的 username 及 loki_key 是否正確。 | ||
- Invalid type. (intent / neuro_kumoko): 意圖的類別只能是 basic 或 advance。 |
||
| - Invalid version.: 不存在指定的 Articut 版本。 | ||
| - Intent already exists.: 已存在相同的意圖名稱。 | ||
| - Intent does not exist.: 意圖不存在,請檢查意圖名稱或建立新意圖。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎出了點狀況。5 分鐘內會自動重啟,請稍後再試一次。如果一樣情況,請聯絡卓騰解決。 | ||
| - It's not a classification project.: 這不是一個分類或分群的專案。 | ||
| - It's not a intent project.: 這不是一個意圖分析的專案。 | ||
| - Model is deploying...: 分類或分群模型正在部屬中。 | ||
| - No matching pattern.: 沒有比對到相同的 pattern。 | ||
| - Only accept names in English (a-z, A-Z), numbers (0-9), and underscore (_).: 不合法的命名規則,只能是大小寫英文、阿拉伯數字及底線。 | ||
| - Project already exists.: 已存在相同的專案名稱。 | ||
- Pattern same as utterance.: 已經存在與 utterance 相同的 pattern。 |
||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| - Reserved key.: 自定義詞典含有保留詞,請更換自定義詞典的 key。 | ||
| - Success!: 任務執行成功。 | ||
- Utterance already exist.: 已存在相同的 utterance。 |
||
- Utterance not found.: 沒有任何的 utterance。 |
||
- Your utterance is too many (over 20 utterance).: utterance 最多支援 20 句。 |
||
| alias_setting | dict | 列出 preview_alias 所套用的 Prompt 別名設定。 |
| loki_key | str | 專案的金鑰。 |
| progress_status | str | 分類或分群模型的部屬狀態。 |
| result | dict | 列出 get_info 的結果。 |
| result_list | list | 列出 get_utterance insert_document insert_utterance match_utterance preview_alias run_alias 的詳細結果。 |
範例程式
{
"url": "https://api.droidtown.co/Loki/Call/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "loki_key",
"value": "%UeS@!%26eUHxZ6N^$LIou3LZZsHO%C",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "text",
"key": "intent",
"value": "Weather",
"placeholder": "Weather",
"required": true
},
{
"type": "select",
"key": "func",
"value": "get_utterance",
"candidate": [
"check_model", "create_project", "create_intent", "deploy_model", "get_info", "get_utterance", "insert_assistant", "insert_document", "insert_utterance", "match_utterance", "preview_alias", "reset_alias", "reset_userdefined", "run_alias", "update_alias", "update_prompt", "update_userdefined"
],
"multiple": false,
"required": true
},
{
"type": "dict",
"key": "data",
"value": {},
"placeholder": {
"type": "basic",
"utterance": ["今天天氣如何?", "下午會不會下雨?"],
"checked_list": ["ENTITY_noun"],
"user_defined": {
"大雨": ["豪雨", "大豪雨", "超大豪雨"],
"中央氣象局": ["氣象局"]
},
"llm": "OpenAI ChatGPT",
"model": "gpt-3.5-turbo",
"api_key": "YOUR_CHATGPT_API_KEY",
"chatbot": true,
"alias": {
"text": {"預言家": ["中央氣象局", "氣象局"]},
"ner": {"id": true, "person": true}
},
"messages": [
{"role": "system", "content": "你是一個天氣助理"},
{"role": "user", "content": "中央氣象局丁小雨:「今天下午梅雨季鋒面報到,氣象局發出超大豪雨特報。」。請問氣象局助理今天下午會不會下雨?"}
],
"prompt": {"user": "請依上文擬定5句回覆「」的句子。"},
"assistant": [
{"title": "大雨", "content": {"NAME": "大雨", "DESC": "24 小時累積雨量達 80 毫米以上,或時雨量達 40 毫米以上之降雨現象。"}},
{"title": "豪雨", "content": {"NAME": "豪雨", "DESC": "24 小時累積雨量達 200 毫米以上,或 3 小時累積雨量達 100 毫米以上之降雨現象。"}},
{"title": "大豪雨", "content": {"NAME": "大豪雨", "DESC": "24 小時累積雨量達 350 毫米以上,或 3 小時累積雨量達 200 毫米以上之降雨現象。"}},
{"title": "超大豪雨", "content": {"NAME": "超大豪雨", "DESC": "24 小時累積雨量達 500 毫米以上之降雨現象。"}}
],
"document": [
{"title": "標題", "content": "內容", "keyword": [], "label": "分類模型標籤"}
],
"source": "分群模型中的句子"
},
"required": true
}
]
}
使用 Loki Command (建議改用 Loki Call)
使用 Loki Command 來爲意圖快速且大量地增加或比對句子。
HTTP Request
POST https://api.droidtown.co/Loki/Command/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Docker 版本無需設定此參數。 |
| loki_key | str | "" | 在本站使用 Loki 服務,建立專案後會取得一個具有 31 字符長度的字串。Docker 版本無需設定此參數。 |
| intent | str | "" | Loki 專案內的意圖名稱。注意!若意圖不存在將會失敗。 |
| utterance | list | [] | 將要新增至意圖的句子。 |
| func | str | insert | 可設置為以下參數: |
- insert: 新增大量的句子。注意!相同結構的句子不會新增。 |
|||
| - match: 比對句子在意圖中是否有相同結構。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利將句子新增至意圖中。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Your utterance is too many (over 20 utterance).: utterance 超過 20 句。 | ||
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid project.: 無效的金鑰。請再檢查一次您的 loki_key 是否正確。 | ||
| - Invalid intent.: 專案內不存在此意圖。請再檢查一次您的 intent 是否正確。 | ||
| - Utterance already exist.: 意圖已存在相同的句子。 | ||
| - Pattern same as Utterance.: 意圖已存在相同結構的句子。 | ||
| - Command execution failed.: 發生不可預期的錯誤,請稍後再試一次。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 |
{
"url": "https://api.droidtown.co/Loki/Command/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "loki_key",
"value": "fvUIyC&anirHZx#NGV%nxXSZbcCfJcS",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "text",
"key": "intent",
"value": "Exchange",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "select",
"key": "func",
"value": "match",
"candidate": ["insert", "match"],
"multiple": false,
"required": true
},
{
"type": "list",
"key": "utterance",
"value": [
"100美金能換多少台幣",
"美金100元可以兌換多少台幣"
],
"placeholder": [
"100美金能換多少台幣",
"美金100元可以兌換多少台幣"
],
"required": true
}
]
}
使用 Loki Utterance (建議改用 Loki Call)
使用 Loki Utterance 來取得意圖中所有句子。
HTTP Request
POST https://api.droidtown.co/Loki/Utterance/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。Docker 版本無需設定此參數。 |
| loki_key | str | "" | 在本站使用 Loki 服務,建立專案後會取得一個具有 31 字符長度的字串。Docker 版本無需設定此參數。 |
| intent_list | list | [] | 預設為空列表,亦即取得所有意圖的句子。取得指定意圖的句子。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利取得意圖的句子。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid project.: 無效的金鑰。請再檢查一次您的 loki_key 是否正確。 | ||
| - Utterance not found.: 意圖不存在任何的句子。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 |
{
"url": "https://api.droidtown.co/Loki/Utterance/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "loki_key",
"value": "fvUIyC&anirHZx#NGV%nxXSZbcCfJcS",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 loki_key。",
"required": true
},
{
"type": "list",
"key": "intent_list",
"value": ["Exchange"],
"placeholder": ["Exchange"],
"required": true
}
]
}
CopyToaster
CopyToaster 服務介紹
CopyToaster 的概念是由家喻戶曉的漫畫「Doraemon」中,未來 21 世紀的道具「記憶吐司」而來。記憶吐司使是能夠複製紙張中的內容,並讓吃下去的人馬上記住複製內容的神奇道具。
CopyToaster 的操作就如同記憶吐司,只要將文件內容複製並且貼上 CopyToaster,就能利用各家 Chatbot 搜尋文件。不僅如此,搜尋結果還會依據使用者做個人化調整,成爲私人文件管理的最佳選擇。
CopyToaster 不單單只是搜尋引擎而已,而是結合了 Articut 中文詞性標記 與 語意計算 (Semantic),經過嚴謹的演算法處理以後,令結果更加符合使用者的期待!
CopyToaster 快速上手指南
登入 CopyToaster
在 https://api.droidtown.co/copyToaster/ 登入開始使用CopyToaster。
建立專案
輸入專案名稱,並點擊[建立專案]。
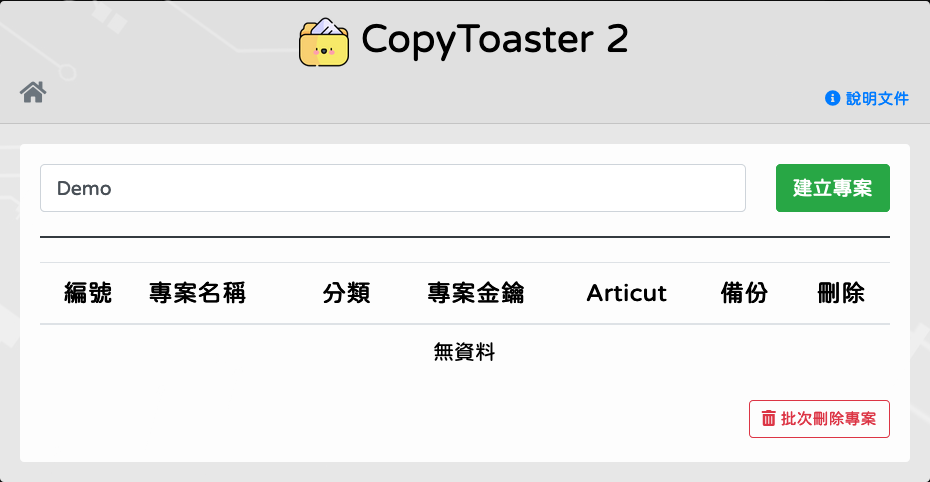
建立分類
進入[專案]後輸入分類名稱,並點擊[建立分類]。
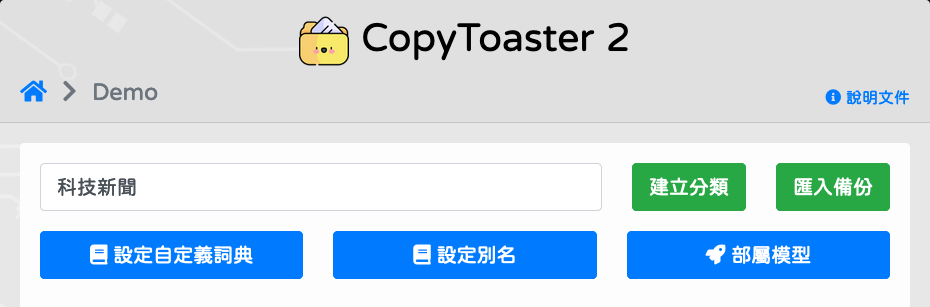
設定自定義詞典
點擊[設定自定義詞典]後填上自定義詞典,亦可點擊[生成自定義詞典]自動產生自定義詞典。
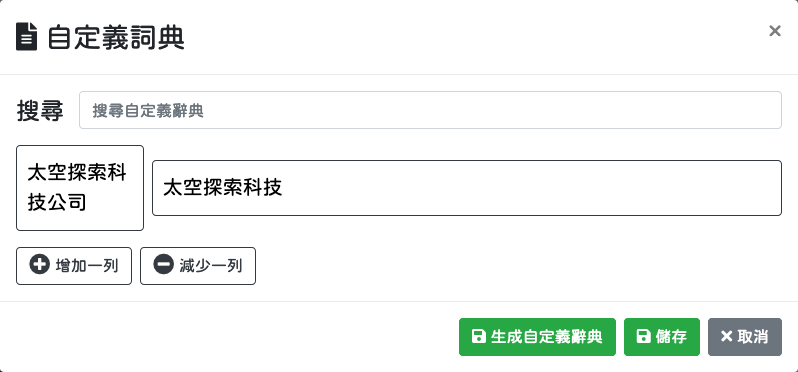
設定別名
點擊[設定別名]後填上別名內容。
下載格式範本並上傳文件
- 進入
[分類]後點擊[JSON]/[EXCEL]/[CSV]下載範本。 將填好文件資料的檔案拖移至
上傳資料區塊。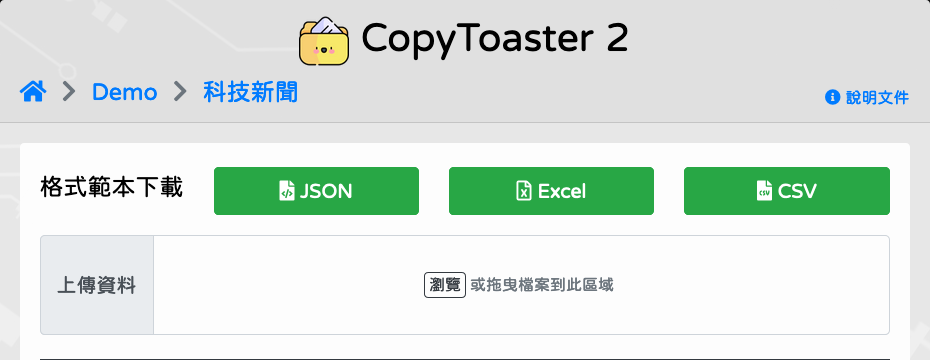
預覽上傳內容後,在畫面最下方點擊
[上傳]將文件上傳,上傳成功後將會看到您的文件清單。
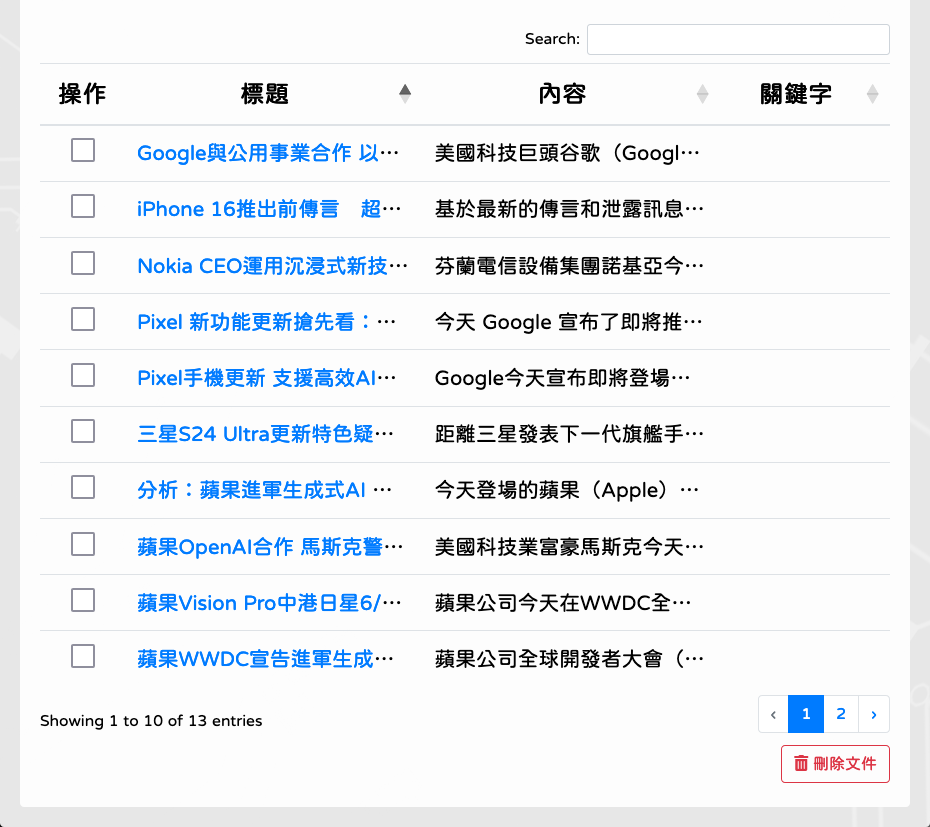
部屬模型
回到
[專案]後點擊[部屬模型]。
[專案]的狀態將顯示製作模型中...,部屬的時間與文件數量成正比,請耐心等候。
當
[專案]不再顯示製作中,代表模型已部屬完成,可以進入[專案]中使用測試工具或使用 CopyToaster API。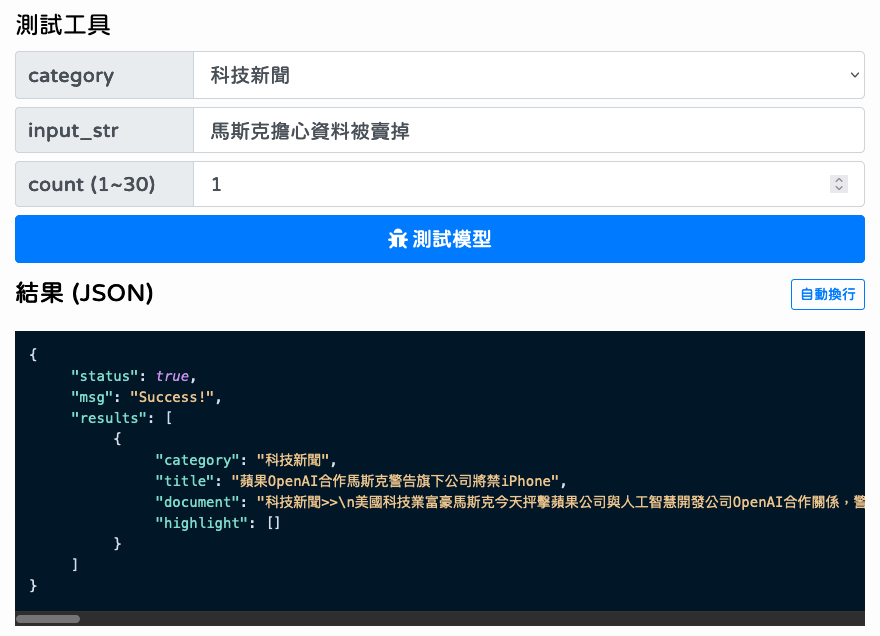
CopyToaster 備份與還原
CopyToaster 備份
在專案列表中點擊[備份圖示]下載備份,檔名為專案.ctb。
CopyToaster 還原
進入
[專案]後點擊[匯入備份],並將備份檔拖曳至上傳備份區塊即可還原。
等待還原完成後,將會看到還原的分類資料。
使用 CopyToaster API
HTTP Request
POST https://api.droidtown.co/CopyToaster/API/V2/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。 |
| copytoaster_key | str | "" | 在本站使用 CopyToaster 服務,建立專案後會取得一個具有 31 字符長度的字串。 |
| category | str | "" | 搜尋的分類名稱。 |
| input_str | str | "" | 要搜尋的文字內容。 |
| count | int | 15 | 指定本次搜尋輸出的判決文數目。預設為 15 篇,上限可達 200 篇。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| progress_status | str | CopyToaster 進度狀態: |
| - processing: CopyToaster 正在搜尋相似的文件。 | ||
| - completed: CopyToaster 已搜尋到相似的文件。 | ||
| - failed: CopyToaster 搜尋不到相似的文件。 | ||
| msg | str | 可能為以下的文字: |
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - CopyToaster is running, please try calling again later.: CopyToaster 正在搜尋結果中,請稍候再呼叫一次 API。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid category.: 專案內不存在這個分類。請再檢查一次您的 category 是否正確。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid project.: 無效的 copytoaster_key。請再檢查一次您的 copytoaster_key 是否正確。 | ||
| - Model is not ready.: 模型尚未部屬。請先部屬模型,並等待模型部屬完成。 | ||
| - No matching document.: 找不到相關的文件。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| - Success!: 成功尋找到相關文件。 | ||
| result_list | list | CopyToaster 搜尋出的相似文件結果。 |
範例程式:
{
"url": "https://api.droidtown.co/CopyToaster/API/V2/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "legaltech@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "copytoaster_key",
"value": "hZYNiEDyd5VCpP(FJS1w@UeRsgLr$QA",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 copytoaster_key。",
"required": true
},
{
"type": "text",
"key": "category",
"value": "臺灣台北地方法院",
"placeholder": "臺灣台北地方法院",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "用LINE恐嚇取財",
"placeholder": "用LINE恐嚇取財",
"required": true
},
{
"type": "int",
"key": "count",
"value": "5",
"placeholder": "15",
"required": false
}
]
}
使用 CopyToaster Call
HTTP Request
POST https://api.droidtown.co/CopyToaster/Call/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。 |
| copytoaster_key | str | "" | 在本站使用 CopyToaster 服務,建立專案後會取得一個具有 31 字符長度的字串。 |
| category | str | "" | 專案的分類名稱。 |
| func | str | "" | 可設置為以下參數: |
| - check_model: 取得模型的部屬狀態。 | |||
| - create_project: 建立新專案。 | |||
| - create_category: 建立新分類。 | |||
| - deploy_model: 部屬模型。 | |||
| - get_info: 取得專案資訊。 | |||
| - insert_document: 新增大量文件。 | |||
| - reset_alias: 清空別名列表。 | |||
| - reset_userdefined: 清空自定義辭典。 | |||
- update_alias: 設定別名列表。原有的別名並不會消失。 |
|||
- update_userdefined: 更新自定義辭典。原有的辭典並不會消失。 |
|||
| data | dict | "" | 根據 func 參數設置以下格式 |
| data.alias | dict | {} | 要更新的別名設定。{key: value_list}func: update_alias |
| data.document | dict | {} | 要新增的文件內容。{title: value, content: value, hashtag: []}func: insert_document |
| data.name | str | "" | 專案名稱。 func: create_project |
| data.user_defined | dict | {} | 要更新的自定義辭典。{key: value_list}func: update_userdefined |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 其值為 True 或 False。 |
| msg | str | 可能為以下的文字: |
| - Authentication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Category already exists.: 已存在相同的分類名稱。 | ||
| - Document already exist.: 已存在相同的文件。 | ||
| - Failure.: 任務執行失敗。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Invalid content_type.: 上傳格式必須為 Json 格式 (application/json)。 | ||
| - Invalid project.: 無效的金鑰。請再檢查一次您的 username 及 copytoaster_key 是否正確。 | ||
| - Invalid category.: 專案內不存在這個分類。請再檢查一次您的分類名稱是否正確。 | ||
| - Model is deploying...: 模型正在部屬中。 | ||
| - Model is not ready.: 模型尚未部屬。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| - Success!: 任務執行成功。 | ||
| - The number of documents exceeds 1000.: 您的文件總數將超過方案上限,請升級您的方案後再新增文件! |
{
"url": "https://api.droidtown.co/CopyToaster/Call/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "copytoaster_key",
"value": ")mvTj8dBKkFpsYOZV16qe5$tyEx@*Rb",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 copytoaster_key。",
"required": true
},
{
"type": "text",
"key": "category",
"value": "科技新聞",
"placeholder": "科技新聞",
"required": false
},
{
"type": "select",
"key": "func",
"value": "get_info",
"candidate": [
"check_model", "create_category", "create_project", "deploy_model", "get_info", "insert_document", "reset_alias", "reset_userdefined", "update_alias", "update_userdefined"
],
"multiple": false,
"required": true
},
{
"type": "dict",
"key": "data",
"value": {},
"placeholder": {
"name": "Demo",
"user_defined": {
"太空探索科技公司": ["太空探索科技"]
},
"document": [
{"title": "標題", "content": "內容", "hashtag": []}
],
"alias": {
"蘋果": ["Apple"]
}
},
"required": true
}
]
}
SPACE
SPACE 服務介紹
空間資訊是語言中「很.重.要」的一部份!
SPACE 是專為台灣設計的 [地址] - [座標] 查詢系統!可進行「座標」與「地址、行政區名稱甚至是景點」之間的雙向查詢。
此外,更整合了中文地址時最常用的:
1. 郵遞區號 (是最新的 3+3 的版本)
2. 中文地址翻譯成英文地址
等功能。
[台灣地點] → [座標]
Geocoding ([台灣地點] → [座標])
能查詢地點 (大安區)、景點 (法鼓山) 或地址 (台北市信義區信義路五段7號)
HTTP Request
POST https://api.droidtown.co/Space/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。 |
| api_key | str | "" | 在本站購買斷詞服務額度,完成付費後取得的一個具有 31 字符長度的字串。 |
| type | str | "" | 可為 geocoding 或 reversegeocoding。指定為 geocoding 時,您將進行地理資訊查詢。若指定為 reversegeocoding 將進行反向地理資訊查詢。如果此項 留白,將無法順利進行 SAPCE 服務。 |
| site | str | "" | type 指定為 geocoding 時,將要送上 Space 進行地理資訊查詢的台灣地點或是台灣地址。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並取得查詢結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成地理資訊查詢作業。 | ||
| - Authtication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid Space key.: 無效的 api_key。請再檢查一次您的 api_key 是否正確。 | ||
| - Insufficient word count balance.: 您帳號下的地理資訊查詢次數餘額不足以處理本次查詢需求。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳地理資訊查詢結果的情況下,您帳號的餘額不會被扣除。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| input_str | str/dict | 進行 geocoding 查詢時,為查詢台灣地點或台灣地址。 |
| balance | int | 您帳號下剩餘可用的查詢次數。 |
| results | list | 列表中含有查詢到的地理資訊 dict。 |
| str | - adm1: 地點/地址所在的中華民國第一行政區名稱。 | |
| str | - adm2: 地點/地址所在的中華民國第二行政區名稱。 | |
| str | - adm2: 地點/地址所在的中華民國第三行政區名稱。 | |
| str | - lat: 地點/地址所在緯度。 | |
| str | - lng: 地點/地址所在經度。 | |
| str | - zipcode: 地址 3+3 郵遞區號。 | |
| str | - addr: 地址英譯。 |
{
"url": "https://api.droidtown.co/Space/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 10 次的公用次數。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 10 次的公用次數。",
"required": true
},
{
"type": "text",
"key": "type",
"value": "geocoding",
"placeholder": "geocoding",
"required": true
},
{
"type": "text",
"key": "site",
"value": "台北市信義區信義路五段7號",
"placeholder": "台北市信義區信義路五段7號",
"required": true
}
]
}
[台灣座標] → [地點]
ReverseGeocoding ([台灣座標] → [地點])
HTTP Request
POST https://api.droidtown.co/Space/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。 |
| api_key | str | "" | 在本站購買斷詞服務額度,完成付費後取得的一個具有 31 字符長度的字串。 |
| type | str | "" | 可為 geocoding 或 reversegeocoding。指定為 geocoding 時,您將進行地理資訊查詢。若指定為 reversegeocoding 將進行反向地理資訊查詢。如果此項 留白,將無法順利進行 SAPCE 服務。 |
| lat | str | "" | type 指定為 reversegeocoding 時,將要送上 Space 進行反向地理資訊查詢的緯度。 |
| lng | str | "" | type 指定為 reversegeocoding 時,將要送上 Space 進行反向地理資訊查詢的經度。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並取得查詢結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利完成地理資訊查詢作業。 | ||
| - Authtication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號是否正確。 | ||
| - Invalid Space key.: 無效的 api_key。請再檢查一次您的 api_key 是否正確。 | ||
| - Insufficient word count balance.: 您帳號下的地理資訊查詢次數餘額不足以處理本次查詢需求。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Internal server error. (Your word count balance is not consumed, don't worry. System will reboot in 5min, please try again later.): 嗯…似乎我們的伺服器出了點狀況。我們正在努力修復中,5 分鐘內會自動重啟,請稍後再試一次。別擔心,在無法正常回傳地理資訊查詢結果的情況下,您帳號的餘額不會被扣除。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 | ||
| input_str | str/dict | 進行 reversegeocoding 時,為查詢台灣座標的地理資訊。 |
| balance | int | 您帳號下剩餘可用的查詢次數。 |
| results | list | 列表中含有查詢到的地理資訊 dict。 |
| str | - adm1: 座標所在的中華民國第一行政區名稱。 | |
| str | - adm2: 座標所在的中華民國第二行政區名稱。 | |
| str | - adm2: 座標所在的中華民國第三行政區名稱。 | |
| str | - lat: 進行查詢的緯度。 | |
| str | - lng: 進行查詢的經度。 | |
| str | - street: 離座標最近的台灣道路。 | |
| str | - place: 離座標 100 公尺內最近的台灣景點,若無回傳 null。 |
{
"url": "https://api.droidtown.co/Space/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 10 次的公用次數。",
"required": true
},
{
"type": "text",
"key": "api_key",
"value": "",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 Api_Key。若使用空字串,則預設使用每小時 10 次的公用次數。",
"required": true
},
{
"type": "text",
"key": "type",
"value": "reversegeocoding",
"placeholder": "reversegeocoding",
"required": true
},
{
"type": "text",
"key": "lat",
"value": "25.03352417862818",
"placeholder": "緯度",
"required": true
},
{
"type": "text",
"key": "lng",
"value": "121.5646039976071",
"placeholder": "經度",
"required": true
}
]
}
Wordy
Wordy 服務介紹
Wordy 中文仿作生成系統是一套獨特的 NLG 輔助工具。和其它文本自動生成系統最大的不同,是 Wordy 力求保留原文的篇章結構!
藉由抽換意義接近的動詞,並在 API 中保留人工介入指定「絕對不能更動的詞彙」以及「人工建議更動的詞彙」,再結合卓騰語言科技精心研發的詞彙、結構抽換系統,一套專為繁體中文語境設計的中文仿作生成系統,於是誕生了!
使用 Wordy API
HTTP Request
POST https://api.droidtown.co/Wordy/API/
參數說明
| 參數 | 型態 | 預設 | 功能 |
|---|---|---|---|
| username | str | "" | 您在本站註冊時所使用的帳號 (email)。 |
| wordy_key | str | "" | 在本站購買 Wordy 服務,完成付費後取得的一個具有 31 字符長度的字串。 |
| input_str | str | "" | 將送上 Wordy 進行改寫的文章內容。 |
| max_num | int | 72 | 預期改寫的最大篇數。注意!上限爲 72 篇。 |
| user_defined | dict | {} | 使用者自定替換詞典,必須是 dictionary 格式。 (e.g. UserDefinedDICT = {"key": ["value1", "value2",...],...})。 |
| fixed_term | str | [] | 禁止替換的詞組列表,必須是 list 格式。 (e.g. fixedTermLIST = ["運動會", "新創公司",...])。 |
回傳內容說明
| 回傳訊息 | 型態 | 說明 |
|---|---|---|
| status | bool | 若成功執行並取得查詢結果,回傳 True;失敗,則回傳 False。 |
| msg | str | 可能為以下的文字: |
| - Success!: 順利執行改寫作業,請靜待通知信件。 | ||
| - Authtication failed.: 無法驗証您的帳號。請再檢查一次您使用的帳號及是否已購買 Wordy。 | ||
| - Invalid wordy_key.: 無效的 wordy_key。請再檢查一次您的 wordy_key 是否正確。 | ||
| - Invalid arguments.: 上傳參數錯誤,請重新檢查上傳時的參數是否符合規則名稱。 | ||
| - Rewrite failed.: 某些原因導致改寫失敗,請再試一次。 | ||
| - Requests per minute exceeded! Each account can only issue 80 requests per minute, please hold for a minute or adjust requesting rate of your program.: 您的帳號已達每分鐘呼叫 80 次上限,請稍後再呼叫。 |
{
"url": "https://api.droidtown.co/Wordy/API/",
"method": "POST",
"type": "json",
"data": [
{
"type": "text",
"key": "username",
"value": "marvin.b@droidtown.co",
"placeholder": "這裡填入您在 https://api.droidtown.co 使用的帳號 email。",
"required": true
},
{
"type": "text",
"key": "wordy_key",
"value": "$-hZ^2=#EC^WAE=gai^i+PJs#sJ5p+u",
"placeholder": "這裡填入您在 https://api.droidtown.co 登入後取得的 wordy_key。",
"required": true
},
{
"type": "text",
"key": "input_str",
"value": "蘋果iphone 15系列終於在今天(13日)正式亮相!台灣列於首波開賣名單,將於9月15日開放預購,9月22日正式發售,售價則為2萬9900元起。不少民眾正在研究該買什麼型號,以及哪時購入最好,有網友指出「購買新iPhone最佳時間點」落在10月底、11月初,並且解釋背後原因。",
"placeholder": "蘋果iphone 15系列終於在今天(13日)正式亮相!台灣列於首波開賣名單,將於9月15日開放預購,9月22日正式發售,售價則為2萬9900元起。不少民眾正在研究該買什麼型號,以及哪時購入最好,有網友指出「購買新iPhone最佳時間點」落在10月底、11月初,並且解釋背後原因。",
"required": true
},
{
"type": "int",
"key": "max_num",
"value": "10",
"placeholder": "72",
"required": false
},
{
"type": "dict",
"key": "user_defined",
"value": {},
"placeholder": {},
"required": false
},
{
"type": "list",
"key": "fixed_term",
"value": [],
"placeholder": [],
"required": false
}
]
}